In questa guida illustriamo le modalità offerte dall’Excel Importer lavorando con un modello d’esempio e dei dati campione. In fondo, nel paragrafo Reference riportiamo l’elenco dei tipi di dato accettati, oltre a un riferimento completo delle validazioni effettuate sui fogli Excel.
Panoramica #
L’Excel Importer consente di caricare, rapidamente e in sicurezza, dati provenienti da fogli di calcolo opportunamente formattati sul database di un’applicazione generata, riducendo i costi di transizione da metodologie gestionali legacy.
Dato un file Excel, il suo contenuto viene letto e processato in un’unica operazione che non richiede ulteriori interventi, in modo simile all’avvio di una Cloudlet. Ciascun foglio di calcolo è una tabella le cui righe rappresentano oggetti di una classe del modello; la tabella nella sua interezza esprime quindi l’ aggiunta di informazioni (append) a un database generato a partire da un modello.
L’Excel Importer supporta tre diverse configurazioni dei fogli, consentendo di aggiungere oggetti semplici, contenenti riferimenti ad altri oggetti esistenti, oppure relazioni tra coppie di oggetti esistenti. Il principio comune a tutte le configurazioni è che ciascuna riga del foglio deve rispettare la struttura dichiarata nel modello usato per generare l’applicazione (e quindi il database): vanno rispettati i tipi, i vincoli e i domini di validazione degli attributi, nonché la cardinalità e il verso delle relazioni attraversate.
Benefici #
Oltre alla rapidità di processamento (è possibile importare agilmente file con milioni di record), l’Excel Importer garantisce i seguenti benefici:
deduzione automatica delle tipologie di dato: non è importante la tipologia della cella, ma il suo contenuto, che viene ricondotto a uno dei tipi supportati;
supporto alle relazioni de-normalizzate: in presenza di associazioni, l’Importer è in grado di riconoscere menzioni multiple dello stesso record analizzando le combinazioni dei valori che compaiono sulle celle, riconducendo automaticamente i dati a una forma normalizzata;
importazione transazionale: in presenza di errori su qualunque foglio del file Excel, tutta l’operazione viene annullata, e il database viene ripristinato allo stato in cui si trovava prima dell’importazione, così da garantire in ogni momento la consistenza dei dati;
segnalazione precisa degli errori: in caso di validazioni fallite, gli errori vengono marcati direttamente sulle celle del foglio, che può essere scaricato ed analizzato, così da facilitare l’individuazione e la risoluzione degli errori.
Scenario d’esempio #
Immaginiamo il seguente scenario: nel nostro modello abbiamo dei clienti (Customer) che effettuano acquisti (Purchase), ciascuno relativo a uno o più prodotti (Product) che sono attualmente in vendita in uno o più dei nostri negozi (Store). Per ciascun Customer indichiamo una città (City) di nascita (puntata dal ruolo birthplace di City) e di residenza (puntata da residence) e memorizziamo le carte di credito (Credit_card) a lui intestate. Tutte le classi sono connesse con associazioni, mentre Credit_card è un part a molti nella composizione con Customer.
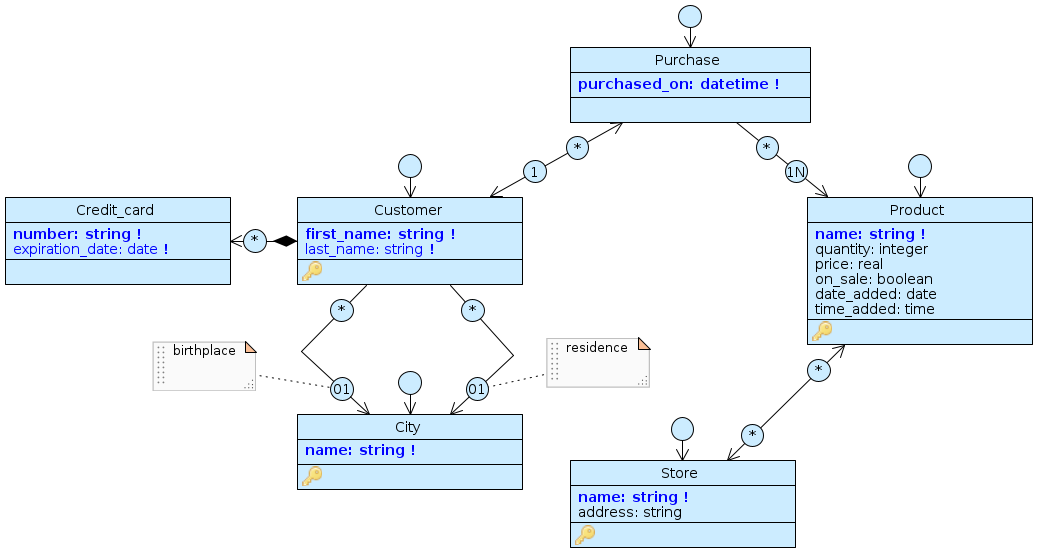
Il modello ExcelImporterShowcase
Per questa guida abbiamo preparato diversi fogli Excel con cui popoleremo tutte queste classi e relazioni usando le diverse configurazioni supportate dal nostro Importer. Per prima cosa, prepariamo un ambiente di lavoro:
scarica il modello cliccando su questo pulsante: ExcelImporterShowcase.xml
crea una nuova Cloudlet;
installa il modello aprendo il
Cloudlet menu(), cliccando sulla voceUpload enginee selezionando il fileExcelImporterShowcase.xmlappena scaricato;clicca sull’icona del database vuota per generare la struttura corrispondente. Questo passo è opzionale: Livebase genererà il database col modello di riferimento non appena importerai il primo file Excel.
Ricordiamo che per importare un file Excel la Cloudlet non deve essere in stato running: prima di importare file Excel, è sempre necessario arrestare la Cloudlet desiderata. Nel resto della guida, ogni importazione dovrà essere preceduta dall’arresto della Cloudlet.
Formato del foglio di lavoro #
L’Importer accetta solamente file con estensione .xlsx (Excel). Un file (detto cartella di lavoro) può contenere uno o più fogli di lavoro; in caso di fogli multipli, questi vengono letti e processati in serie, in ordine di comparsa nella cartella.
L’Importer lavora sempre in modalità append: ciascun foglio di lavoro aggiunge eventualmente nuovi record a quelli già esistenti nel database di destinazione, facendo riferimento a elementi già definiti del relativo modello. Non è possibile modificare informazioni già esistenti sul database (cambiare valori di attributi, rimuovere oggetti o ruoli, ecc.).
L’Importer può riconoscere tre diversi formati di foglio, ciascuno dei quali rappresenta un diverso scenario di append:
Flat sheet: il formato più semplice, fa riferimento a una classe del modello e consente di aggiungere nuovi record a essa, specificando per ciascuno di essi i valori che dovranno essere assunti in corrispondenza di ogni attributo;
Reference sheet: fa anche esso riferimento a una classe; consente di aggiungere nuovi record a essa e contestualmente associarli a oggetti esistenti di altre classi raggiungibili con ruoli (anche dette classi satellite);
Relation sheet: fa riferimento a una relazione di associazione tra due classi del modello; consente di associare tra loro coppie di oggetti già presenti nelle due classi.
Il formato scelto per un foglio dipende dal nome del foglio e dal contenuto della riga di intestazione.
Nome del foglio #
La classe del modello puntata da Flat sheet e Reference sheet è detta main class. Per questi due formati, il nome del foglio deve coincidere col nome della main class (ad esempio Product se la main class è Product).
Per il Relation sheet, il nome del foglio deve contenere i nomi delle due classi unite nell’associazione, secondo la sintassi <Class1Name>-<Class2Name> (ad esempio Product-Shop per l’associazione tra Product e Shop). Se tra le due classi è presente una sola associazione, non c’è ambiguità e l’ordine con cui compaiono i nomi non è rilevante. Se sono presenti più associazioni, diventa allora necessario usare la sintassi <Class1Name>-<Class2Name>|<Class2RoleName> in cui si specifica il nome del ruolo target attraversato. L’ordine in questo caso è rilevante e va indicata per ultima la classe target del ruolo (ad esempio, Customer-City|birthplace rappresenta il ruolo birthplace di City nell’associazione con Customer, e la disambiguazione è necessaria perché è presente anche il ruolo residence).
Riga di intestazione #
Indipendentemente dal formato, ciascun foglio di lavoro deve contenere una riga di intestazione (header) in cui sono riportati, su colonne distinte e in ordine arbitrario, gli identificatori degli attributi puntati dal foglio. Per gli attributi della main class l’identificatore coincide col nome dell’attributo (ad esempio, la colonna name nel foglio Product corrisponde all’attributo name di Product).
Per Reference sheet e Relation sheet, le colonne contenenti riferimenti verso attributi di oggetti esistenti devono essere intestate con *<ClassName>.<AttributeName>; il prefisso * indica che la colonna è un riferimento, mentre <AttributeName> è il nome di un attributo che appartiene a un vincolo di unicità, o chiave, della classe <ClassName>. Il riferimento deve necessariamente puntare una chiave della classe, così da identificarne univocamente gli oggetti nel foglio ed evitare ambiguità nell’associazione (ad esempio, *Product.name è un riferimento all’attributo univoco name di Product).
In caso di chiavi formate da più attributi, tutti gli attributi coinvolti devono comparire come riferimenti nell’intestazione; ad esempio, *Customer.first_name e *Customer.last_name devono essere necessariamente usate in coppia quando si punta a un oggetto Customer, perché la chiave è formata dalla coppia first_name e last_name.
Anche in questo caso vi è ambiguità nella relazione attraversata dal riferimento, perché sono presenti più relazioni; è dunque necessario includere nel riferimento il ruolo della classe puntata (target), con la sintassi *<ClassName>.<AttributeName>|<RoleName> (ad esempio, *City.name|birthplace è un riferimento all’attributo univoco name di City passando per il ruolo birthplace di City nell’associazione con Customer, e la disambiguazione è necessaria perché è presente anche il ruolo residence).
Ignorare fogli e colonne #
I fogli e le colonne di intestazione che iniziano con il prefisso # non vengono processati dall’Importer; questo consente, ad esempio, di includere nello stesso file fogli con scopi diversi, usare delle colonne per annotare i record, o “spegnere” delle colonne/attributi.
Inoltre, se un attributo accetta valori nulli e tutti i record da importare non hanno valori in sua corrispondenza, è possibile omettere del tutto la colonna corrispondente non indicandola nell’intestazione.
Importare Flat sheet #
Ora che sappiamo come è fatta l’intestazione di un foglio di lavoro, possiamo avvalerci di alcuni esempi per approfondire gli aspetti che riguardano il contenuto vero e proprio delle celle. Per prima cosa, importiamo dei dati nel nostro modello facendo uso di un Flat sheet. Clicca sul bottone seguente per scaricarlo:
Prima di procedere con l’importazione, diamo un’occhiata al file aprendolo in un editor compatibile (MS Excel, LibreOffice Calc, etc.).
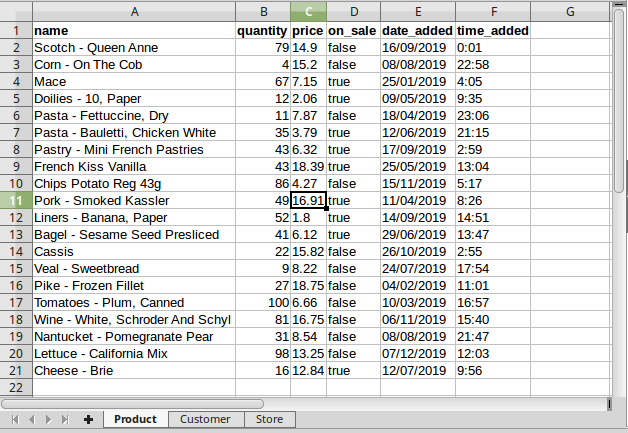
La cartella di lavoro FlatSheetImport
Possiamo notare alcune cose:
- sono presenti tre fogli, rispettivamente:
Product,CustomereStore; - per ciascuno sono riportati nell’header tutti e soli gli attributi delle rispettive classi del modello, in quanto nessuno di essi è prefissato con
*. Tutti e tre i fogli sono dunque dei Flat sheet; - ciascuna riga rappresenta un nuovo oggetto/record che importeremo nella main class di riferimento del foglio. Le celle in corrispondenza di ciascuna colonna faranno assumere il valore indicato all’attributo con il medesimo nome della colonna, come specificato nell’header;
- il contenuto delle celle è coerente col tipo di dato scelto per ciascun attributo. Per esempio, nel foglio
Productle scelte del tipo di dato compiute dall’Importer sono le seguenti:- stringhe in corrispondenza di
name; - interi in corrispondenza di
quantity; - numeri decimali in corrispondenza di
price(assumendo che il prezzo sia in dollari, o euro); - valori binari (true o false) in corrispondenza di
on_sale; - date in corrispondenza di
date_added; - orari in corrispondenza di
time_added.
- stringhe in corrispondenza di
- i valori di tutti i record rispettano i vincoli definiti sul modello. Per esempio, nel foglio
Productnon ci sono valori nulli in corrispondenza diname, in quanto abbiamo imposto un vincolo required sul relativo attributo. Lo stesso vale per Customer, che ha il required su first_name e last_name, e per Store, che lo presenta su name. Sempre suProduct, alcune celle delle altre colonne sono invece vuote, il che è consentito perché non abbiamo vincoli required su questi attributi.
Importa i fogli aprendo il Cloudlet menu (), cliccando sulla voce Upload excel e selezionando dalla finestra il file FlatSheetImport.xlsx appena scaricato.
Al termine dell’operazione, il conteggio degli oggetti del database dovrebbe essersi aggiornato e apparire come in figura (in caso contrario, apri il menu Dashboard e seleziona l’opzione Refresh).
Infine, esaminiamo gli oggetti importati attraverso il client GraphiQL, a cui accediamo facendo clic sul pulsante API & Public URLs presente nel descrittore della Cloudlet e poi sul link here (assicurandoci di aver prima avviato la Cloudlet). Dopo esserci autenticati come l’utente amministratore, sottomettiamo la seguente query:
Importare Reference sheet #
Finora abbiamo importato oggetti su tre classi (Product, Customer e Store) tra loro isolate. Abbiamo preparato il terreno per importare oggetti della classe Purchase, che mette in relazione un customer e uno o più product. Per fare ciò abbiamo bisogno di un Reference sheet. Clicca sul bottone per scaricarlo:
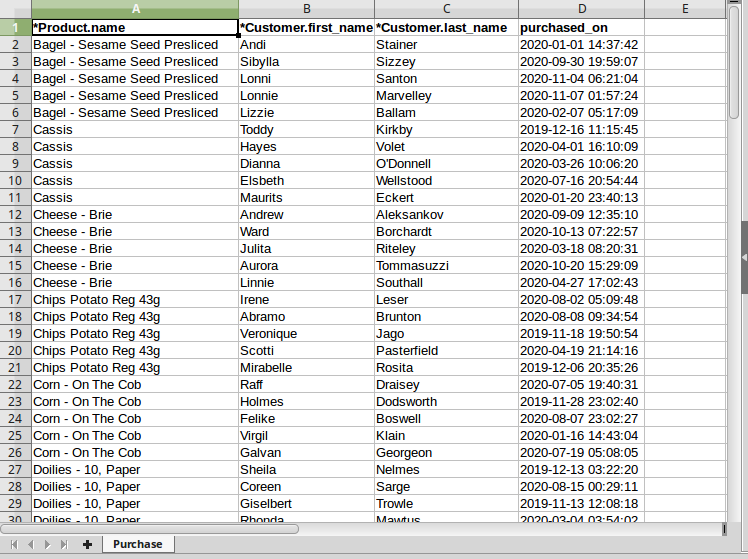
La cartella di lavoro ReferenceSheetImport
Esaminando il file possiamo notare i seguenti aspetti:
- è presente un solo foglio chiamato
Purchase; - nell’header c’è l’unico attributo di Purchase: purchased_on. Le rimanenti colonne sono occupate dai riferimenti verso le classi satellite: Product, puntata da
name, e Customer, puntata dafirst_nameelast_name; - per entrambe le classi satellite sono riportati tutti e soli gli attributi che appartengono ad almeno un vincolo di unicità: per
Productil vincolo è suname, mentre per Customer è sulla coppia(first_name, last_name); - poiché sono presenti sia riferimenti sia attributi nativi, il file è un Reference sheet;
- ciascuna riga rappresenta un nuovo oggetto/record che importeremo nella main class Purchase ( valorizzato con il contenuto della cella di
purchased_on) e che assoceremo contestualmente a un Customer e a uno o più Product, puntati rispettivamente dalle chiavi delle celle di (*Customer.first_name,*Customer.last_name) e*Product.name; - anche qui il contenuto delle celle è coerente con i tipi di dato:
purchased_onè un valore datetime, mentre i valori dei riferimenti sono gli stessi degli attributi puntati. - poiché nel nostro modello entrambe le relazioni (verso Customer e Product) hanno cardinalità minima 1, non sono presenti righe con riferimenti vuoti; se così non fosse stato, sarebbe stato accettabile importare delle purchase con celle vuote in corrispondenza di queste colonne;
È importante notare che nel foglio stiamo lavorando con dati de-normalizzati: dato che la relazione verso Product è a molti, ci sono righe in cui sia purchased_on sia la chiave su Customer hanno valori duplicati, e cambia solamente il valore su *Product.name. In questi casi, l’Excel Importer è in grado di riconoscere automaticamente che queste righe fanno riferimento allo stesso oggetto purchase.
Importa il foglio come fatto in precedenza. Al termine dell’operazione, il conteggio degli oggetti del database dovrebbe essere aumentato ulteriormente per via dell’aggiunta dei nuovi record su Purchase (in caso contrario, apri il menu Dashboard e seleziona l’opzione Refresh).
Reference sheet e oggetti part #
Vediamo ora un utilizzo particolare del Reference sheet. Sfruttando il fatto di poter associare un oggetto contestualmente alla sua creazione, possiamo usare questo formato per importare oggetti part in una composizione. Le regole sono semplici: dobbiamo scrivere il foglio dal “punto di vista” della classe part facendo riferimento alla chiave dell’oggetto main, che nel caso della composizione non può accettare valori nulli.
Procediamo quindi nell’importare oggetti di Credit_card, che è in composizione (part a molti) con Customer (whole), anche qui facendo uso di un Reference sheet:
ReferenceSheet_CompositionImport.xlsx
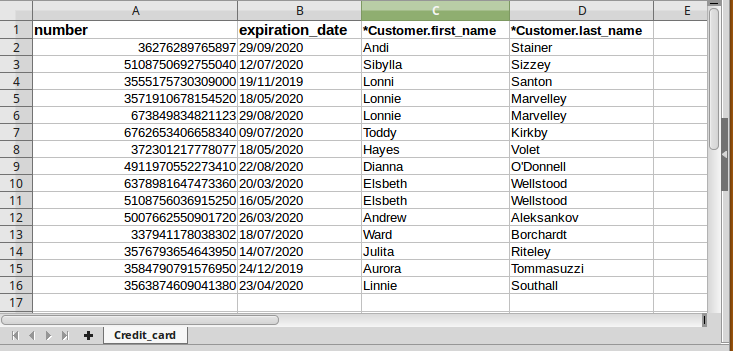
La cartella di lavoro ReferenceSheet_CompositionImport
In modo simile all’esempio precedente, abbiamo un unico foglio Credit_card contenente un riferimento alla chiave di Customer costituita dalla coppia first_name e last_name. Le altre colonne sono invece relative agli attributi di Credit_card, e il loro contenuto è compatibile con il tipo di dato scelto e con il fatto che sia number sia expiration_date sono required nel modello.
Anche in questo caso, trattandosi di una composizione, non abbiamo valori nulli per i riferimenti a Customer (non ha senso che esistano carte di credito senza clienti). Chiaramente, il record whole è sempre un oggetto univoco; nel nostro caso, una carta di credito appartiene a uno e un solo cliente, anche se nella vita reale ciò può non essere vero. In ogni momento, quindi, l’importazione deve rispettare la regola per cui gli oggetti referenziati devono essere già presenti nel database.
Importa il foglio come fatto in precedenza. Al termine dell’operazione, il conteggio degli oggetti del database dovrebbe essere aumentato ulteriormente per via dell’aggiunta dei nuovi record su Credit card (in caso contrario, apri il menu Dashboard e seleziona l’opzione Refresh).
Reference sheet e riferimenti a ruoli multipli #
Vediamo un ultimo esempio più complesso: stavolta, importiamo oggetti di una main class associandoli contestualmente a classi satellite che hanno più di un ruolo target. In questo scenario usiamo prima un Flat sheet per aggiungere delle City, e successivamente un Reference sheet per aggiungere dei Customer (nota: si tratta di nuovi oggetti rispetto a quelli che abbiamo importato in precedenza!) e associarli a City:
ReferenceSheet_MultiRoleImport_Flat.xlsx
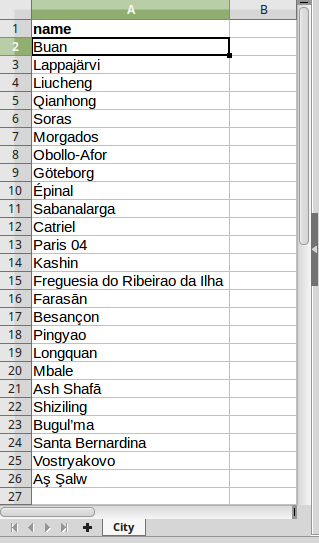
La cartella di lavoro ReferenceSheet_MultiRoleImport_Flat
ReferenceSheet_MultiRoleImport_Reference.xlsx
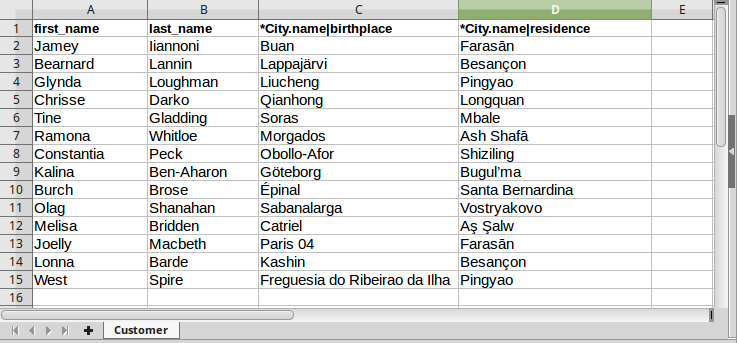
La cartella di lavoro ReferenceSheet_MultiRoleImport_Reference
Esaminando i due file notiamo alcune cose:
- ciascuno di essi contiene un foglio, rispettivamente
CityeCustomer; entrambi questi fogli si riferiscono alle corrispondenti classi del modello; - nell’header di
Cityc’è il suo unico attributo name. Il foglio del primo file è dunque un Flat sheet e importerà degli oggetti City; - nell’header di
Customerci sono i soliti attributi required first_name e last_name, più due riferimenti a City per mezzo dell’attributo name che fa parte della sua chiave (dunque il secondo file contiene un Reference sheet). I riferimenti sono disambiguati specificando il ruolo uscente verso City (birthplace e residence):*City.name|birthplacee*City.name|residence;
Importiamo i due file nell’ordine corretto, effettuando prima l’upload di ReferenceSheet_MultiRoleImport_Flat.xlsx e successivamente di ReferenceSheet_MultiRoleImport_Flat.xlsx, così da permettere all’Importer di seguire correttamente i riferimenti del secondo foglio che puntano ai record del primo. Al termine della procedura, il conteggio degli oggetti del database dovrebbe essere aumentato ulteriormente per via dell’aggiunta dei nuovi record su City e Customer (in caso contrario, apri il menu Dashboard e seleziona l’opzione Refresh).
Importare relation sheet #
Resta da esaminare l’ultimo formato di foglio riconosciuto dall’Importer, il Relation sheet. Come abbiamo accennato, la differenza principale con gli altri due formati sta nel fatto che qui puntiamo una associazione e non una main class, e dunque non aggiungiamo nuovi oggetti nel database. Procediamo quindi nello stabilire nuove relazioni tra gli oggetti importati in precedenza delle classi Store e Product:
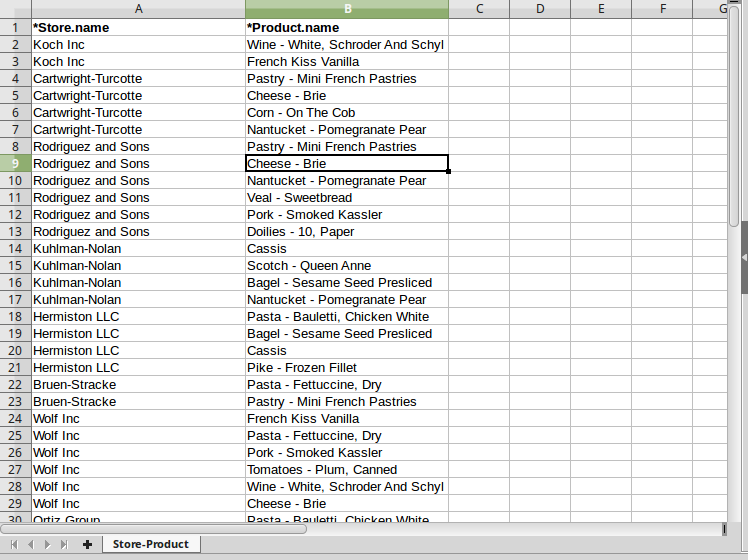
La cartella di lavoro RelationSheetImport
Possiamo notare i seguenti aspetti:
- è presente un foglio denominato
Store-Productche punta all’unica relazione esistente tra le classi Store e Product. Data l’assenza di ambiguità dei ruoli, non è stato necessario specificare il nome del ruolo target puntato, e di fatto non è rilevante l’ordine scelto per indicare i nomi delle classi coinvolte nell’associazione (sarebbe stato accettato ancheProduct-Store); - nell’header sono presenti solo i riferimenti a Store e Product, che puntano ciascuno al rispettivo attributo/chiave name;
- ciascuna riga rappresenta una nuova istanza dell’associazione puntata dal foglio. Le celle in corrispondenza delle colonne di riferimento specificano tra quali oggetti deve essere instaurata la relazione, in base ai valori che i suddetti assumono in corrispondenza dell’attributo puntato.
Importa il foglio come fatto in precedenza. Chiaramente, dal momento che non sono stati importati nuovi oggetti ma sono stati associati tra loro oggetti esistenti, al termine dell’operazione il conteggio degli oggetti del database resterà invariato.
Importare fogli non validi #
Finora abbiamo sempre importato fogli validi, sia nel formato che nel contenuto. In quest’ultimo esempio vogliamo mostrare il comportamento dell’Excel Importer quando almeno un foglio del file processato viola una o più regole tra quelle controllate. Proviamo dunque a importare il seguente Flat sheet:
Per una volta, fidiamoci del file scaricato e importiamolo direttamente nella Cloudlet senza esaminarlo. Come previsto, l’importazione non andrà a buon fine e otterremo il messaggio d’errore in figura:
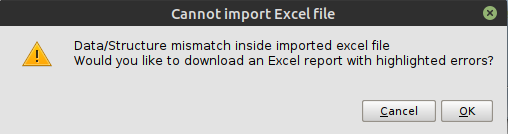
L’Importer comunica un disallineamento tra la struttura del nostro file e il modello. Clicchiamo su OK e procediamo nello scaricare una replica del file di input; questo contiene delle marcature in corrispondenza dei record che sono andati in errore, che ci aiuteranno a individuare e correggere gli errori. Puoi scegliere la posizione e il nome con cui intendi salvare il file marcato, ma in questo caso lascia il nome di default. Apriamo il file marcato offertoci dalla Dashboard ed esaminiamolo:
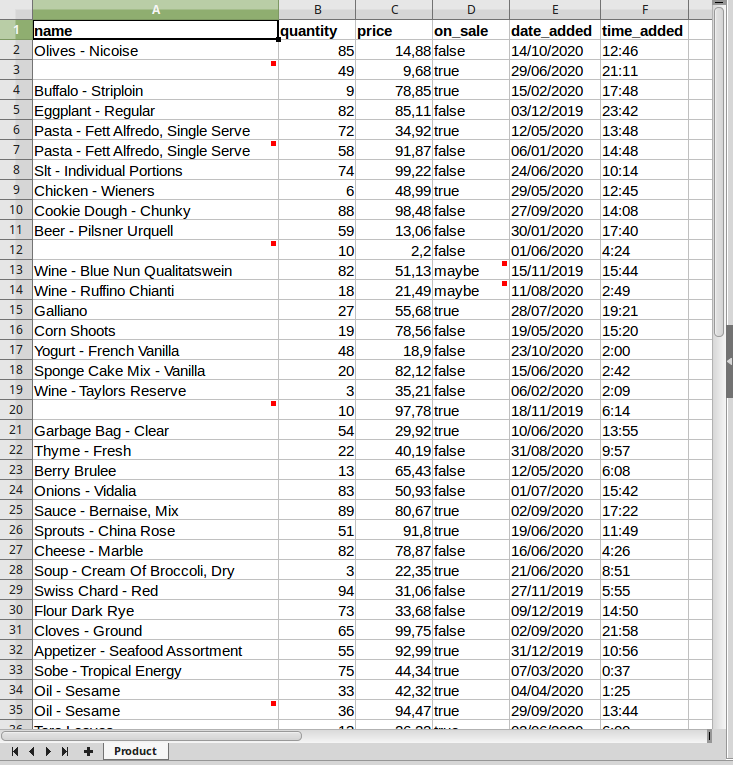
Le marcature sul foglio FlatSheetImport_Error
Questo file contiene un solo Flat sheet sulla classe Product, su cui possiamo notare la presenza di piccoli riquadri rossi in corrispondenza dei valori che sono andati in errore. Passando con il mouse su di essi, apparirà un commento che spiegherà in modo più dettagliato tale errore:
- le righe 3, 12, 20 sono vuote in corrispondenza dell’attributo name: l’Importer le interpreterà come nulle, violando il vincolo required che abbiamo imposto nel modello;
- le righe 6-7, 34-35 presentano dei duplicati in corrispondenza dell’attributo name, su cui è imposto un vincolo unique;
- le righe 13 e 14, in corrispondenza dell’attributo on_sale, presentano il valore “maybe”: questo valore non è un booleano accettabile.
Reference #
Tipi di dato #
Per ogni colonna specificata in un foglio Excel, l’Importer ne riconosce (o inferisce) il tipo analizzando la prima cella non vuota e non nulla, con lo scopo di determinare alcuni parametri di conversione che serviranno a tradurre il contenuto di quella cella in un formato compatibile con il database.
Il riconoscimento dei tipi segue il seguente ordine:
- numero decimale (Real). Innanzitutto si verifica che la cella contenga unicamente cifre, successivamente si riconosce il separatore dei decimali ed eventualmente quello delle migliaia, in base a delle convenzioni. Una volta fatto questo, viene determinato il numero di cifre raggruppate dalle migliaia e quello delle cifre decimali;
- numero intero (Integer). L’inferenza è simile a quella per i decimali, con l’unica differenza che viene identificato solo il separatore delle migliaia;
- data (Date). La data riportata nella cella viene confrontata con un elenco di pattern riconosciuti;
- orario (Time). L’orario riportato nella cella viene confrontato con un elenco di pattern riconosciuti;
- data e ora o timestamp (Datetime). Il timestamp riportato nella cella viene confrontato con un elenco di pattern riconosciuti;
- valori booleani (Boolean). Il contenuto è confrontato con un insieme di coppie che rappresentano il vero e il falso. Verrà utilizzata la prima coppia per cui si verificherà un match per uno dei valori di verità;
- stringhe (String). Se l’algoritmo di inferenza non riconosce nessuno dei tipi soprastanti, il contenuto è interpretato come stringa e verrà memorizzato nel database così com’è.
Nel momento in cui viene riconosciuto il tipo per una colonna, l’Importer si aspetta di trovare dei valori compatibili in tutte le celle successive. Se questo non si verifica, verrà segnalato un errore di tipo.
Validazioni e marcature #
Nel caso in cui venga importato un file Excel che presenta errori per almeno uno dei suoi fogli, la Dashboard mostrerà questa finestra di dialogo:
Confermando, l’utente ha la possibilità di scaricare una replica del file Excel che si è tentato di importare, la quale presenterà una serie di marcature in corrispondenza di tutti gli errori riscontrati. Tali marcature appaiono come dei piccoli riquadri rossi che occupano l’angolo superiore destro delle celle interessate: passando il mouse sopra le celle marcate è possibile mostrare un commento che riporta un dettaglio sul tipo di errore riscontrato.
L’Importer è attualmente in grado di riconoscere e segnalare i seguenti errori:
| Tipologia vincolo | Errore | Descrizione | Marcatura |
|---|---|---|---|
| Attributo | Violazione di tipo | L’Importer non riesce a ricondurre il contenuto di una cella al tipo dell’attributo corrispondente | Viene marcata la cella corrispondente |
| Attributo | Violazione lunghezza stringhe | Una cella contiene una stringa la cui lunghezza non soddisfa i vincoli imposti sul relativo attributo | Viene marcata la cella corrispondente |
| Attributo | Violazione vincolo required | L’Importer incontra una cella vuota in corrispondenza della colonna relativa a un attributo required | Viene marcata la cella vuota |
| Attributo | Violazione vincolo di unicità | Il foglio contiene oggetti che presentano valori duplicati in corrispondenza delle combinazioni di attributi che appartengono a vincoli di unicità. La verifica è sia a livello di foglio che di database | Vengono marcate le celle con i valori duplicati |
| Riferimento | Riferimento inconsistente (Reference sheet) | Un riferimento multi-attributo ha solo alcuni dei suoi valori nulli, invece di averli tutti o nessuno | Vengono marcate le celle del riferimento inconsistente |
| Riferimento | Riferimento inconsistente (Relation sheet) | Un riferimento multi-attributo non ha valorizzati tutti i suoi attributi | Vengono marcate le celle del riferimento inconsistente |
| Riferimento | Riferimento “appeso” (dangling) | Un riferimento punta a un oggetto non esistente nel database | Vengono marcate le celle del riferimento appeso |
| Riferimento | Multi-whole | Il foglio contiene oggetti part in composizione con più di un whole, che hanno più di un riferimento valorizzato presso questi ultimi | Vengono marcate le celle di tutti i riferimenti a ulteriori whole dopo il primo incontrato |
| Riferimento | Violazione vincolo di unicità di ruolo | Il foglio contiene oggetti che presentano valori duplicati in corrispondenza dei riferimenti relativi a ruoli con cardinalità 1, coinvolti in vincoli di unicità. La verifica è sia a livello di foglio sia di database | Vengono marcate le celle con i riferimenti duplicati |
| Ruolo | Violazione di cardinalità | A seguito dell’importazione di oggetti o istanze di associazione, le cardinalità dirette o inverse per i suddetti risultano violate | Vengono marcati tutti gli oggetti che determinano la violazione |