In this guide we illustrate the ways offered by the Excel Importer by working with an example engine and sample data. At the bottom, in the Reference paragraph we give the list of accepted data types, as well as a full reference of the validations performed on Excel sheets.
Overview #
The Excel Importer enables data from appropriately formatted spreadsheets to be quickly and securely loaded onto the database of a generated application, reducing the cost of transitioning from legacy management methodologies.
Given an Excel file, its contents are read and processed in a single operation that requires no further intervention, similar to starting a Cloudlet. Each spreadsheet is a table whose rows represent objects of a model class; the table in its entirety then expresses the addition of information (append) to a database generated from an engine.
The Excel Importer supports three different sheet configurations, allowing you to add simple objects, containing references to other existing objects, or relationships between pairs of existing objects. The principle common to all configurations is that each row of the sheet must respect the structure declared in the engine used to generate the application (and therefore the database): the types, constraints and validation domains of the attributes must be respected, as well as the cardinality and direction of the relationships crossed.
Benefits #
In addition to speed of processing (you can easily import files with millions of records), the Excel Importer guarantees the following benefits:
automatic deduction of data types: it is not the cell type that is important, but its content, which is brought back to one of the supported types;
support for de-normalized relations: in the presence of associations, the Importer is able to recognize multiple mentions of the same record by analyzing the combinations of values that appear on the cells, automatically leading the data back to a normalized form;
transactional importation: in the presence of errors on any sheet of the Excel file, the whole operation is cancelled, and the database is restored to the state it was in before the importation, so that data consistency is guaranteed at all times;
precise error marking: in case of failed validations, errors are marked directly on the cells of the sheet, which can be downloaded and analyzed, so as to facilitate the detection and resolution of errors.
Sample scenario #
Let’s imagine the following scenario: in our engine we have customers (Customer) who make purchases (Purchase), each related to one or more products (Product) that are currently on sale in one or more of our stores (Store). For each Customer we indicate a city (City) of birth (pointed by the birthplace role of City) and of residence (pointed by residence) and we store the credit cards (Credit_card) in his name. All classes are connected with associations, while Credit_card is a part-to-many in composition with Customer.
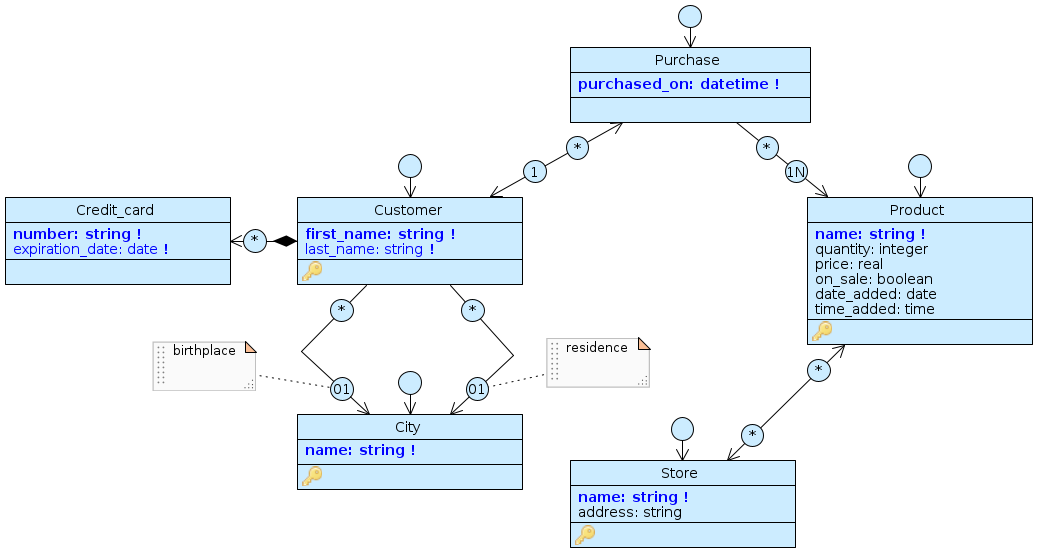
The ExcelImporterShowcase template
For this guide, we have prepared several Excel sheets with which we will populate all these classes and relationships using the different configurations supported by our Importer. First, let’s prepare a working environment:
download the engine by clicking on this button: ExcelImporterShowcase.xml
creates a new Cloudlet;
install the engine by opening the
Cloudlet menu(), clicking on theUpload engineitem and selecting the fileExcelImporterShowcase.xmljust downloaded;click on the empty database icon to generate the corresponding structure. This step is optional: Livebase will generate the database with the referenced engine as soon as you import the first Excel file.
Remember that to import an Excel file the Cloudlet must not be in running state: before importing Excel files, you should always stop the desired Cloudlet. In the rest of the guide, every import must be preceded by stopping the Cloudlet.
Worksheet Format #
The Importer only accepts files with the .xlsx (Excel) extension. A file (called workbook) can contain one or moreworksheets; in case of multiple sheets, they are read and processed serially, in order of appearance in the folder.
The Importer always works in append mode: each worksheet eventually adds new records to those already existing in the target database, referring to already defined elements of the related engine. It is not possible to modify already existing information on the database (change attribute values, remove objects or roles, etc.).
The Importer can recognize three different sheet formats, each representing a different append scenario:
Flat sheet: the simplest format, it refers to an engine model class and allows you to add new records to it, specifying for each of them the values that should be assumed at each attribute;
Reference sheet: also refers to a class; allows you to add new records to it and simultaneously associate them to existing objects of other classes accessible with roles (also called satellite classes);
Relation sheet: refers to an association relation between two classes of the engine model; it allows to associate between them pairs of objects already present in the two classes.
The format chosen for a sheet depends on the sheet name and the content of the header line.
Sheet name #
The model class pointed to by Flat sheet and Reference sheet is called the main class. For these two formats, the sheet name must match the name of the main class (e.g. Product if the main class is Product).
For the Relation sheet, the sheet name must contain the names of the two classes joined in the association, according to the syntax <Class1Name>-<Class2Name> (e.g. Product-Shop for the association between Product and Shop). If there is only one association between the two classes, there is no ambiguity and the order in which the names appear is not relevant. If there are multiple associations, it then becomes necessary to use the syntax <Class1Name>-<Class2Name>|<Class2RoleName> in which the name of the target_ rule traversed is specified. The order in this case is relevant, and the target class of the role should be specified last (e.g., Customer-City|birthplace represents the birthplace role of City in association with Customer, and disambiguation is necessary because the residence role is also present).
Header Row #
Regardless of format, each worksheet must contain a header row (header) in which the identifiers of the attributes pointed to by the sheet are listed in separate columns and in arbitrary order. For attributes of the main class, the identifier coincides with the name of the attribute (e.g., the name column in the Product sheet corresponds to the name attribute of Product).
For Reference sheet and Relation sheet, columns containing references to attributes of existing objects must be headed with *<ClassName>.<AttributeName>; the prefix * indicates that the column is a reference, while <AttributeName> is the name of an attribute that belongs to a unique constraint, or key, of the class <ClassName>. The reference must necessarily point to a key of the class, so as to uniquely identify its objects in the sheet and avoid ambiguity in the association (e.g., *Product.name is a reference to the unique attribute name of Product).
In the case of keys formed by multiple attributes, all the attributes involved must appear as references in the header; for example, *Customer.first_name and *Customer.last_name must necessarily be used in pairs when pointing to a Customer object, because the key is formed by the pair first_name and last_name.
Also in this case there is ambiguity in the relation crossed by the reference, because there are more than one relation; it is therefore necessary to include in the reference the role of the pointed class (target), with the syntax *<ClassName>. <AttributeName>|<RoleName>`` (e.g.,*City.name|birthplace` is a reference to the unique attribute name of City passing through the birthplace role of City in the association with Customer, and disambiguation is necessary because the residence role is also present).
Ignore sheets and columns #
Sheets and header columns beginning with the prefix # are not processed by the Importer; this allows, for example, sheets with different purposes to be included in the same file, columns to be used to annotate records, or columns/attributes to be “turned off”.
Also, if an attribute accepts invalid values and all records to be imported have no values matching it, it is possible to omit the corresponding column altogether by not indicating it in the header.
Import Flat sheets #
Now that we know what a worksheet header looks like, we can make use of some examples to delve into the actual cell content. First, let’s import some data into our engine by making use of a Flat sheet. Click on the following button to download it:
Before proceeding with the import, let’s take a look at the file by opening it in a compatible editor (MS Excel, LibreOffice Calc, etc.).

The FlatSheetImport workbook
We can notice a few things:
- there are three sheets, respectively:
Product,CustomerandStore; - for everyone are brought back in the header all and only the attributes of the respective classes of the engine model, in how much none of they is prefixed with
*. All three sheets are therefore Flat sheets; - each row represents a new object/record that we will import into the main class of the sheet reference. The cells at each column will have the value given to the attribute with the same column name, as specified in the header;
- the contents of the cells are consistent with the data type chosen for each attribute. For example, in the
Productsheet, the data type choices made by the Importer are as follows:- strings corresponding to
name; - integer corresponding to quantity;
- decimal numbers for
price(assuming the price is in dollars or euros); - binary values (true or false) for
on_sale; - date for
date_added; - time for
time_added.
- strings corresponding to
- the values of all records respect the constraints defined on the engine. For example, in the
Productsheet, there are no null values forname, because we have imposed a required constraint on its attribute. The same is true for Customer, which has the required on first_name and last_name, and for Store, which has it on name. Also onProduct, some cells in the other columns are blank instead, which is allowed because we have no required constraints on these attributes.
Import the sheets by opening the Cloudlet menu (), clicking on Upload excel and selecting from the window the file FlatSheetImport.xlsx just downloaded.
When finished, the database object count should have updated and appear as in the figure (if not, open the Dashboard menu and select the Refresh option).

Import Reference sheets #
So far we’ve imported objects on three classes (Product, Customer, and Store) that are isolated from each other. We have set the stage to import objects from the Purchase class, which relates a customer and one or more_products_. To do this we need a Reference sheet. Click on the button to download it:

The ReferenceSheetImport workbook
Examining the file we can notice the following aspects:
- there is only one sheet called
Purchase; - in the header there is the only attribute of Purchase: purchased_on. The remaining columns are occupied by references to the satellite classes: Product, pointed by
name, and Customer, pointed byfirst_nameandlast_name; - for both satellite classes all and only attributes that belong to at least one uniqueness constraint are reported: for
Productthe constraint is onname, while for Customer it is on the pair(first_name, last_name); - since both references and native attributes are present, the file is a Reference sheet;
- each line represents a new object/record that we will import into the main class Purchase ( valorized with the cell contents of
purchased_on) and associate contextually with a Customer and one or more_Product_, respectively pointed to by the cell keys of (*Customer.first_name,*Customer.last_name) and*Product.name; - again, the contents of the cells are consistent with the data types:
purchased_onis a datetime value, while the values of the references are the same as the pointed attributes. - since in our engine both relations (towards Customer and Product) have minimum cardinality 1, there are no rows with empty references; if this were not the case, it would have been acceptable to import purchased with empty cells in correspondence of these columns;
It is important to note that in the sheet we are working with de-normalized data: since the relationship to Product is many, there are rows where both purchased_on and the key on Customer have duplicate values, and only the value on *Product.name changes. In these cases, the Excel Importer can automatically recognize that these rows refer to the same purchase object.
Imports the sheet as done previously. When finished, the database object count should have increased further due to the addition of the new records on Purchase (if not, open the Dashboard menu and select the Refresh option).
Reference sheet and part objects #
Let’s now look at a particular use of the Reference sheet. Taking advantage of the fact that we can associate an object contextually to its creation, we can use this format to import part_ objects into a composition. The rules are simple: we must write the sheet from the “point of view” of the part class by referring to the key of the main object, which in the case of the composition cannot accept null values.
We then proceed to import objects from Credit_card, which is in composition (part to many) with Customer (whole), again making use of a Reference sheet:
ReferenceSheet_CompositionImport.xlsx
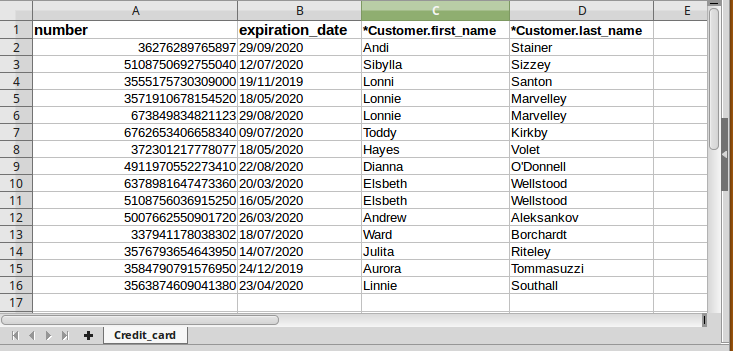
The ReferenceSheet_CompositionImport workbook
Similar to the previous example, we have a single sheet Credit_card containing a reference to the key of Customer consisting of the pair first_name and last_name. The other columns are related to the attributes of Credit_card, and their content is compatible with the chosen data type and with the fact that both number and expiration_date are required in the model.
Again, since this is a composition, we do not have null values for Customer references (it does not make sense that credit cards exist without customers). Clearly, the whole record is always a unique object; in our case, a credit card belongs to one and only one customer, although in real life this may not be true. At all times, therefore, the import must respect the rule that referenced objects must already be present in the database.
Import the sheet as done previously. At the end of the operation, the database object count should have increased further due to the addition of the new records on Credit card (if not, open the Dashboard menu and select the Refresh option).
Reference sheet and references to multiple roles. #
Let’s look at one last, more complex example: this time, we import objects from a main class while associating them with satellite classes that have more than one target role. In this scenario we first use a Flat sheet to add Cities, and then a Reference sheet to add Customers (note: these are new objects compared to the ones we imported previously!) and associate them with Cities:
ReferenceSheet_MultiRoleImport_Flat.xlsx
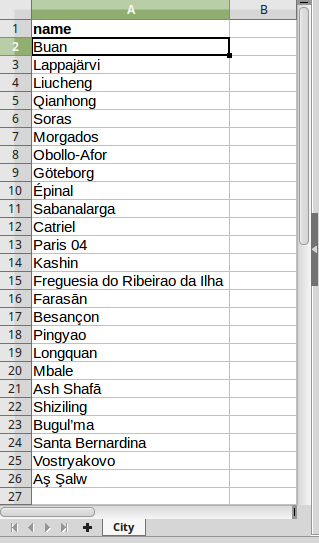
The ReferenceSheet_MultiRoleImport_Flat workbook
ReferenceSheet_MultiRoleImport_Reference.xlsx
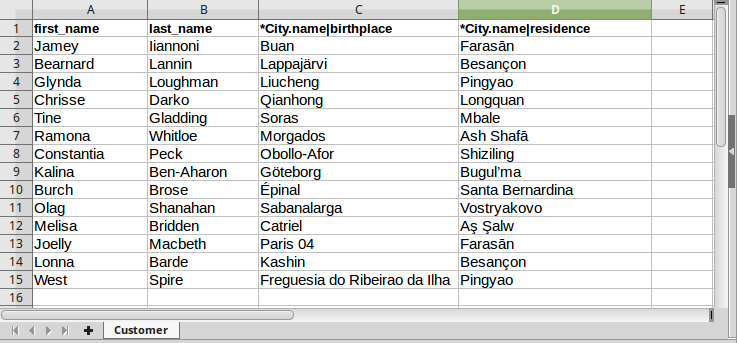
The ReferenceSheet_MultiRoleImport_Reference workbook
Examining the two files we notice a few things:
- each of them contains a sheet,
CityandCustomerrespectively; both of these sheets refer to the corresponding classes in the engine; - in the header of
Citythere is its only attribute name. The sheet in the first file is therefore a Flat sheet and will import City objects; - in the header of
Customerthere are the usual required attributes first_name and last_name, plus two references to City by means of the name attribute which is part of its key (thus the second file contains a Reference sheet). References are disambiguated by specifying the outgoing role to City (birthplace and residence):*City.name|birthplaceand*City.name|residence;
We import the two files in the correct order, first uploading ReferenceSheet_MultiRoleImport_Flat.xlsx and then ReferenceSheet_MultiRoleImport_Flat.xlsx, so that the Importer can correctly follow the references of the second sheet pointing to the records of the first. At the end of the procedure, the database object count should have increased further due to the addition of the new records on City and Customer (if not, open the Dashboard menu and select the Refresh option).
Import relation sheets #
It remains to examine the last sheet format recognized by the Importer, the Relation sheet. As we have mentioned, the main difference with the other two formats is that here we are pointing to an association and not to a main class, and therefore we are not adding new objects to the database. We then proceed to establish new relationships between the previously imported objects of the Store and Product classes:

The RelationSheetImport workbook
We can notice the following aspects:
- there is a sheet named
Store-Productthat points to the only existing relationship between the Store and Product classes. Given the absence of role ambiguity, it was not necessary to specify the name of the target role pointed to, and in fact the order chosen to indicate the names of the classes involved in the association is not relevant (Product-Storewould have been accepted as well); - in the header there are only references to Store and Product, each pointing to its respective name attribute/key;
- each row represents a new instance of the association pointed to by the sheet. The cells in correspondence to the referenced columns specify between which objects the relationship is to be established, based on the values that the aforementioned take on at the pointed attribute.
Import the sheet as you did before. Clearly, since no new objects have been imported but existing objects have been associated with each other, at the end of the operation the database object count will remain unchanged.

The detail form of a Store, with associated Products
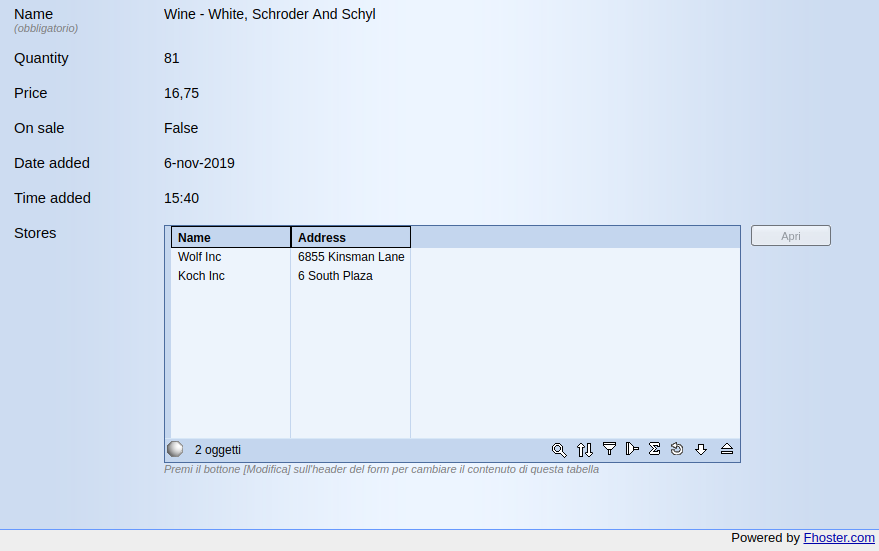
The detail form of a Product, with the associated Stores
Import invalid sheets #
So far we have always imported valid sheets, both in format and content. In this last example we want to show the behavior of the Excel Importer when at least one sheet of the processed file violates one or more of the checked rules. So let’s try to import the following Flat sheet:
For once, let’s trust the downloaded file and import it directly into Cloudlet without examining it. As expected, the import will fail and we will get the error message in the figure:
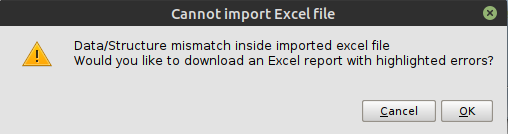
The Importer communicates a mismatch between the structure of our file and the model. We click OK and proceed to download a replica of the input file; this contains markings at the records that went wrong, which will help us detect and correct the errors. You can choose the location and name under which you want to save the marked file, but in this case leave the default name. Let’s open the marked file offered to us by the Dashboard and examine it:

The markings on the FlatSheetImport_Error
This file contains a single Flat sheet on the Product class, on which we can see the presence of small red boxes at the values that have gone into error. Passing with the mouse on them, a comment will appear explaining in more detail this error:
- the lines 3, 12, 20 are empty in correspondence of the attribute name: the Importer will interpret them as null, violating the required constraint that we have defined in the engine;
- the lines 6-7, 34-35 present some duplicates in correspondence of the attribute name, on which is imposed a unique constraint;
- lines 13 and 14, in correspondence of the on_sale attribute, have the value “maybe”: this value is not an acceptable boolean.
Reference #
Data Types #
For each column specified in an Excel spreadsheet, the Importer recognizes (or infers) its type by analyzing the first non-empty and non-zero cell, with the purpose of determining some conversion parameters that will be used to translate the contents of that cell into a database-compatible format.
Type recognition follows the following order:
- decimal number (Real). First we check that the cell contains only digits, then we recognize the decimal separator and possibly the thousand separator, according to conventions. Once this is done, the number of digits grouped by thousands and the number of decimal digits are determined;
- integer number (Integer). The inference is similar to that for decimals, except that only the separator of the thousands is identified;
- date (Date). The date given in the cell is compared to a list of recognized patterns;
- time (Time). The time reported in the cell is compared with a list of recognized patterns;
- date and time or timestamp (Datetime). The timestamp reported in the cell is compared with a list of recognized patterns;
- Boolean values (Boolean). The content is compared against a set of pairs representing true and false. The first pair for which a match occurs for one of the truth values will be used;
- String (String). If the inference algorithm does not recognize any of the above types, the content is interpreted as a string and will be stored in the database as is.
The moment the type is recognized for a column, the Importer expects to find compatible values in all subsequent cells. If this does not occur, a type error will be reported.
Validations and markings #
If you import an Excel file that has errors on at least one of its sheets, the Dashboard will display this dialog box:
By confirming, the user has the possibility to download a replica of the Excel file that was attempted to be imported, which will present a series of markings in correspondence with all the errors found. These markings appear as small red squares that occupy the upper right corner of the cells concerned: by passing the mouse over the marked cells it is possible to show a comment detailing the type of error found.
The Importer is currently able to recognize and report the following errors:
| Constraint type | Error | Description | Marking |
|---|---|---|---|
| Attribute | Type Violation | The Importer cannot match the content of a cell to the type of the corresponding attribute | The corresponding cell is marked |
| Attribute | String length violation | A cell contains a string whose length does not meet the constraints imposed on the corresponding attribute | The corresponding cell is marked |
| Attribute | Violation of required constraint | The Importer encounters an empty cell in the column related to a required attribute | The empty cell is marked |
| Attribute | Violation of unique constraint | The sheet contains objects that have duplicate values at combinations of attributes that belong to uniqueness constraints. The check is both at sheet and database level | Cells with duplicate values are marked |
| Reference | Inconsistent reference (Reference sheet) | A multi-attribute reference has only some of its values null, instead of having all or none | The cells of the inconsistent reference are marked. |
| Reference | Inconsistent reference (Relation sheet) | A multi-attribute reference does not have all of its attributes valued | The cells of the inconsistent reference are marked. |
| Reference | Hung reference (dangling) | A reference points to an object that does not exist in the database | Cells of the hung reference are marked |
| Reference | Multi-whole | The sheet contains part objects in composition with more than one whole, which have more than one reference valued at them | Cells of all references to additional whole after the first encountered are marked |
| Reference | Role unique constraint violation | The sheet contains objects that have duplicate values in correspondence with references related to roles with cardinality 1, involved in uniqueness constraints. The check is both at sheet and database level | Cells with duplicate references are marked |
| Role | Cardinality violation | Following the import of objects or association instances, the direct or inverse cardinality for these objects are violated | All objects that cause the violation are marked |