In the previous lesson #
We took advantage of vertical, horizontal, and per-user-profile partitioning techniques to build application views, each centered on a particular picture listed in the User Profiles section of our example scenario, thus obtaining a small, complete management application.
However, the design choices made so far have assumed that our application will not undergo significant changes during its operation, whereas in a real-world scenario, requests for new features or bug fixes could involve very complex maintenance tasks, for which the automated strategies offered by Livebase are not sufficient.
A limitation of automatic evolutionary maintenance #
Speaking of evolutionary maintenance, we stated that
One of the main challenges in modifying a running application is to be careful to not break anything or make the data in the database inconsistent.
Let’s reason about the relationship between structure and content of a database: the elements we can define in the Database Schema (classes, attributes and relationships) are the containers of our information. As we know, with the Livebase Designer we can change the dimension (domain and cardinality) or the information type (data type) of these containers; however, these are structural changes that do not directly affect the data they contain.
When the containers are not empty ’ i.e., the model is tied to a database ’ such changes directly affect the pre-existing data. Although it is always possible to control the effects of the changes thanks to the alignment tool, the dependence of the information on the structure of the database is a constraint that limits our expressive power, and can therefore represent an obstacle for the evolution of the system.
- What happens if we want to move the information to a different container? For example, I would like to move the information associated with a relationship between two classes to an attribute of another class.
You already know the answer to this question: in Modeling with relationships: when we promoted some attributes of the class Employee (position and team) by reifying them into new satellite classes, the data previously stored in the columns for those attributes were orphaned and we had to give them up. Clearly this operation is acceptable as long as you stay in a sandbox context, but how should we have behaved if this were a production system?
In order not to lose that data we should have:
- Allowed for a short period of time the co-existence of the “new” and “old” containers, adjusting the namespace appropriately;
- Regenerated the application and update the database structure;
- Moved the position and team information for each employee into the new classes by hand.
Clearly, this solution cannot scale, because it introduces potential ambiguities and may be too slow a process with large amounts of data. Is there a smart approach to solving this problem?
![]() So in this article, let’s see how to deal with evolutionary maintenance scenarios that Livebase is not able to handle automatically. The tool we use is the Database Importer, a utility that allows us to manage the database of a Cloudlet independently from all its other components; in practice, we can import/export the entire database in the form of an SQL file and operate directly on that file. This allows us to quickly perform a mass manipulation on the data to which we want to “change container”.
So in this article, let’s see how to deal with evolutionary maintenance scenarios that Livebase is not able to handle automatically. The tool we use is the Database Importer, a utility that allows us to manage the database of a Cloudlet independently from all its other components; in practice, we can import/export the entire database in the form of an SQL file and operate directly on that file. This allows us to quickly perform a mass manipulation on the data to which we want to “change container”.
Importing data using SQL files #
First, let’s prepare the working environment: we need a Cloudlet, a model, and some data to work with.
At this point you should have the final version of the TutorialEngine model available. If not, download it by clicking on the button next to it; then drag the XML file to the Dashboard to import it into the library.
Install the engine model on a Cloudlet: it can be a new Cloudlet or the Cloudlet Workforce we’ve been working with so far. If you opt for a new Cloudlet, once you have installed the model you need to create the database and then empty it, by right-clicking on its icon and selecting Clear: this procedure serves to avoid that the Enum class Activity\type, introduced in the lesson Model queries and filters, interferes with the subsequent data import process. However, if you wish to continue using Workforce, you will only need to empty the existing database by doing Clear. In any case, remember to realign the database to the model by resolving any compatibility issue.
Now we need to import some data. For this exercise we have prepared a file containing a test dataset for the Workforce database: download it by clicking on the button next to it, then open the database panel of the destination Cloudlet, click on Upload and select the SQL file you just downloaded.
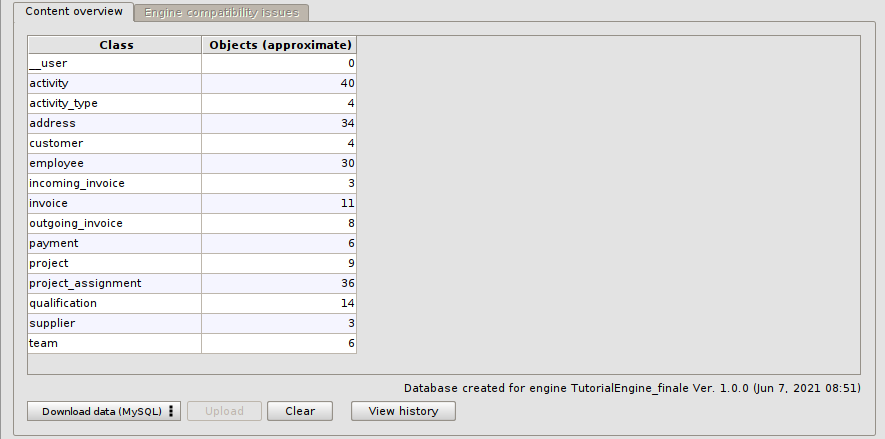
The database will be populated with 208 records, distributed as shown in the picture among all the classes in the model. In practice, the file we used contains several INSERT SQL queries for each table mapped to the database.
Generalizing a complex relation #
Let’s take a look in the Designer at TutorialEngine: in this context we ignore most of the details of the model ’ whose requirements are described in the Example Scenario ’ and focus on the evolution of a portion of the Database Schema .
Switch to the Staff diagram and observe the relationship between the Project and Employee classes.
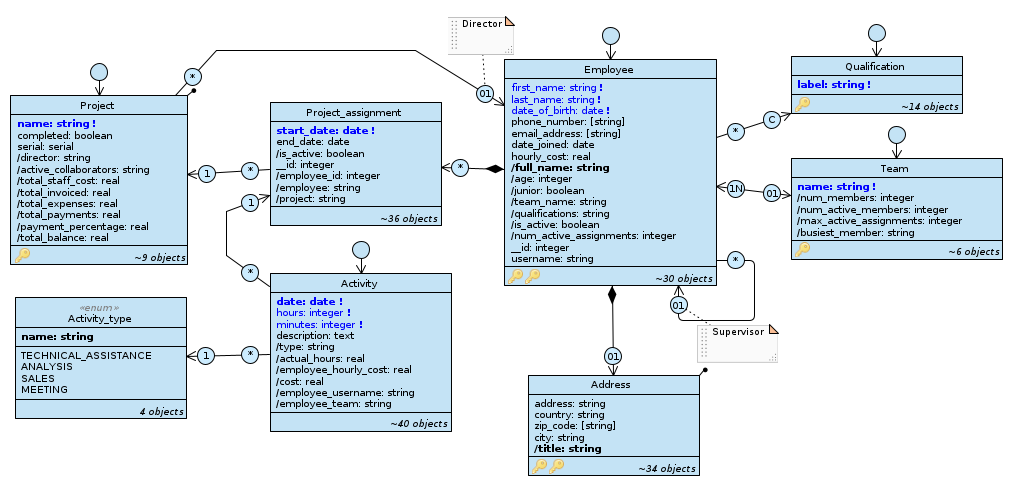
The Staff diagram.
For each project, we can indicate the employee who fills the role of director; this is appropriately chosen by filtering rules at the application level ’ among the employees who at that moment are assigned to the project via an active assignment ’ represented by the assignment with the Project_assignment class, part class of Employee.
The information that binds employee and project are the start/end dates of assignment and the property of being or not being a director; in particular, the latter is expressed with a special relationship from Project to Employee. One of the problems of this representation is that it cannot be accessed from the employee list but only from the project list; another is that it is not flexible enough:
- What would we need to do if we wanted to represent and dynamically manage other roles that may be employed in the project as well, such as technical manager, business analyst, or general staff?
Clearly adding other special association roles doesn’t solve the problem, because it would result in increasing the complexity of the model and force us to rebuild it every time. We can’t even use an Enum like we did with Activity_type in the Model Queries and Filters lesson, because we don’t know a priori all the possible Project_role that can be assumed by an employee. The solution again is encapsulate the information in a generic satellite class, However, unlike what we did previously, we will now keep the existing relationship until we can safely remove it.
Modify the data model #
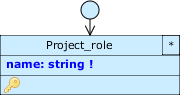
First, create the Project_role class with the name attribute as in the picture, set as required, object title and unique.
Clearly we can’t have an employee fill a role for a project who doesn’t work on it; therefore, this information is related to the employee’s assignment:
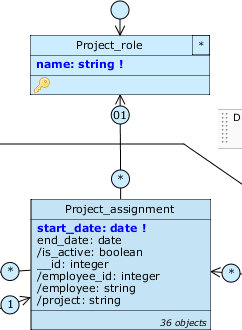
Add a unidirectional association from Project\assignment to Project\role, rename the roles to assignments and role_ and set the cardinality of the latter to (01) (the role is unique for each assignment, the constraint is relaxed so as not to introduce alignment problems with the underlying data). After that, drag name to Project_assignment and rename the query to /role.
This way, whenever we create a new assignment for an employee, we’ll also need to specify what role he or she will play in that project.
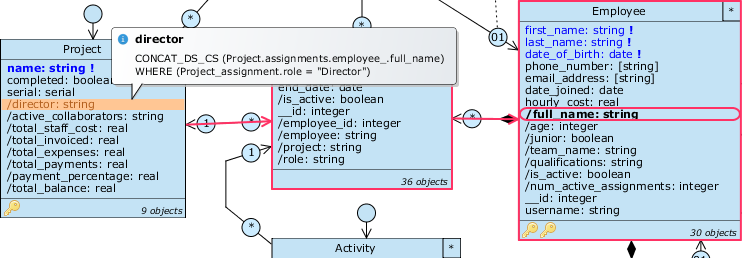
Now that we have a new structure, we can make some no-cost changes to the existing one: let’s start by redirecting the query /director to Project showing the director’s name, currently going by Project.role:
- Right click on
/directorand selectReroute, then choose the pathProject.assignments.employee_.full_name; since the new path traverses roles to many, the Query expression editor will open to ask us how to aggregate the query multiple values. - Clearly we are interested in showing the name of only one employee, so we need to make sure that there is only one assignment with role “director” for each project. First, add the filter condition
Project_assignment.role = "Director"and aggregate with theConcat distinctfunction (to represent the contents of the /full_name string); this will show all employees with the director role for that project.
Now let’s deal with redefining the rule that governs the number of “director” roles per project, so that /director shows at most one employee’s name. We need to define a Class warning to prevent saving new assignment with role “director” if there is already one associated with the same project.
- First of all, we have to count how many directors there are for each project; however, since the Class warning can only use attributes present in the class, we have to store this information inside Project_assignment and to do this we proceed in a slightly different way than usual, creating a reentrant query: from the Class menu of Project_assignment select
New derived attribute’Query, expand the pathProject_assignment.project_.assignments.__idand aggregate withCount distinct. - Here too we define a filter condition on the role name, but we have to pay particular attention to the choice of the class: along the path, in fact, we cross twice Project_assignment: the first time it is a single object (on which will be stored /numdirectors), the second time it is the set of assignments associated to a project through the role Project.assignments.
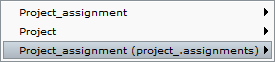
You can verify this by opening the expression editor of the filter condition and clicking on the : notice how Project_assignment is shown twice, with the second one specifying the reentrant path project._assignments. Since we need to filter on this set, expand this entry, select theProject_assignment.project_.assignments.roleattribute, and complete the expression by adding= "Director". Confirm the creation of the query and rename it to/num_directors. - As you can see in the picture, the query travels through the association in both directions, exiting and reentering on the same class.
In this way, the assignments assigned to the same project will all have the same value of /num_directors, this effect is desired, because it serves the warning to be evaluated correctly for each object.  Switch to the Administration application view and add a blocker warning on Project_assignment named
Switch to the Administration application view and add a blocker warning on Project_assignment named tooManyDirectorswith the expressionnum_directors > 1; check theSaveNewandSaveExistingactions, type the message “There would be too many director assignments for the selected project.” and confirm.- Propagate the warning to other views: from the Class warnings manager, select it and check the
Copy warning to other applicationsoption.
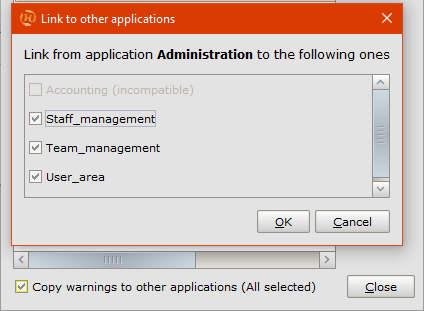
- From the panel that appears, select the three compatible views, i.e. those in which Project_assignment is enabled. Once this is done, confirm and return to the diagram.
By doing so, we’ve set the stage for the introduction of the new project roles. Now all we have to do is align the existing data related to project managers. Save and close the Designer.
Align data via SQL #
The database shows some low severity issues, related to the creation of the new table Project_role: solve them without problems, then we proceed to manipulate our data.
We need to modify the SQL file that populates the database. In this case we don’t need to re-download it from the Cloudlet, since we haven’t made any changes to the database content; therefore we can work directly on the Workforce_data.sql file you downloaded earlier.
Since we are working on a fairly small database, for this part of the exercise we can work directly on the content of the file; therefore, open it using any text editor (we used Sublime Text).
1. Edit the SQL file #
The file looks like in the picture. As you can see, it contains several INSERT INTO queries, one for each table in the database related to a class in the model. In addition, there are some additional tables that map many-to-many relationships (join tables), such as the one between Employee and Qualification (employee_qualification).
Let’s start by adding new records project_role; in this regard, note how the queries also make explicit the values assumed by the Platform attributes of each object (such as _id, _createdBy, _createdOn, and so on). Therefore, we will need to fill in those fields as well. Add the following lines to the end of the file that add the Director, Technical Manager, Account Manager, Staff roles.
INSERT INTO `project_role` (`__id`, `__createdby`, `__createdon`, `__lastmodifiedby`, `__lastmodifiedon`, `__ownedby`, `__ownedon`,`name`) VALUES
(29901,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Director'),
(29902,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Technical Manager'),
(29903,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Account Manager'),
(29904,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Staff');
Information such as creation date and author of the changes can be any, as long as they respect the format of the columns they are going to populate. A separate issue is the __id, which as we know must be unique throughout the database. We’ll come back to this topic later.
Now we need to locate the INSERT INTO 'project' query and take note of the values present under the id_director column, i.e., the director IDs. For example, the project with ID 21001 (“Mars Rocket”) has as director the employee 11011 (“Mal Cragell”); in fact, we can find a record with that ID under the query INSERT INTO 'employee'.
The director-project pairs are then as shown in the table opposite. As you can see, some projects do not have a director; in that case, the value of the id_director column is NULL, as well as that of the _id_director_associatedby and _id_director_associatedon columns, related to the platform attributes of the single association.
| Employee | Project |
|---|---|
11011 | 21001 |
11003 | 21002 |
11004 | 21005 |
11021 | 21008 |
11008 | 21009 |
That done, we need to modify the records in the INSERT INTO ‘project_assignment’ query related to the assignments of the directors of each project. Given the structure of our model, we certainly know that these records exist.
The new relationship goes from multiple project_assignments to a single project_role, so in the objects of the first class there will be a key that references the role (called a foreign key). First, we need to edit the query header and add this key in the queue, along with the two platform attributes of the association. The following line:
INSERT INTO `project_assignment` (
`__id`,
`__createdby`,
`__createdon`,
`__lastmodifiedby`,
`__lastmodifiedon`,
`__ownedby`,
`__ownedon`,
`start_date`,
`end_date`,
`id__employee_`,
`id__project_`,
`id__project___associatedby`,
`id__project___associatedon`
) VALUES
Becomes
INSERT INTO `project_assignment` (
`__id`,
`__createdby`,
`__createdon`,
`__lastmodifiedby`,
`__lastmodifiedon`,
`__ownedby`,
`__ownedon`,
`start_date`,
`end_date`,
`id__employee_`,
`id__project_`,
`id__project___associatedby`,
`id__project___associatedon`,
`id__role_`, --- new
`id__role___associatedby`, --- new
`id__role___associatedon` --- new
) VALUES
Then, we need to locate the assignments where the id_\employee and id_\project pairs coincide with the ones in the table above. To these records we must associate the project_role “Director”, i.e. the one we added with the ID 29901.
In the table beside we have reported the triples employee-project-assignment on which we make this change. Note that for these records must be specified also the platform attributes associatedBy and associatedOn, while for all other records ’ since the constraint is relaxed ’ we can indicate NULL for all three new fields.
| Employee | Project | Assignment |
|---|---|---|
11011 | 21001 | 25512 |
11003 | 21002 | 25520 |
11004 | 21005 | 25505 |
11021 | 21008 | 25522 |
11008 | 21009 | 25509 |
The resulting new query is as follows, where we have highlighted the changes. Copy it and replace it with the existing one.
INSERT INTO `project_assignment` (`__id`, `__createdby`, `__createdon`, `__lastmodifiedby`, `__lastmodifiedon`, `__ownedby`, `__ownedon`, `start_date`, `end_date`, `id__employee_`, `id__project_`, `id__project___associatedby`, `id__project___associatedon`,`id__role_`, `id__role___associatedby`, `id__role___associatedon`) VALUES
(25501,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-08-16','2018-02-13',11000,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25502,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-02','2019-02-22',11001,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25503,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-08-07','2018-09-01',11002,21003,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25504,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-04','2018-09-17',11003,21004,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25505,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-17','2019-01-30',11004,21005,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25506,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-13','2018-05-25',11005,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25507,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-10','2018-09-07',11006,21007,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25508,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-04-21','2018-05-24',11007,21008,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25509,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-25','2019-01-03',11008,21009,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25510,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-10-28','2018-04-14',11009,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25511,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-21','2019-02-10',11010,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25512,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-09','2019-02-05',11011,21001,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25513,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-02-13','2018-05-08',11012,21005,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25514,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-26','2018-05-03',11013,21005,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25515,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-11-29','2018-04-19',11014,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25516,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-08-23','2017-10-30',11015,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25517,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-21','2019-01-01',11016,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25518,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-09-24','2018-11-21',11017,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25519,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-06-20','2018-11-21',11018,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25520,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-09-29','2018-03-13',11019,21002,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25521,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-09','2018-06-02',11020,21003,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25522,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-09-27','2018-11-30',11021,21008,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25523,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-06-13','2017-12-01',11022,21009,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25524,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-02-16','2018-04-08',11023,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25525,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-06-04','2017-10-19',11024,21005,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25526,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-04-12','2018-09-22',11025,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25527,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-08-10','2018-11-30',11026,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25528,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-01-27','2018-08-18',11027,21008,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25529,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-03','2018-11-14',11028,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25530,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-10-15','2018-03-07',11029,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25531,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-10','2018-11-03',11002,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25532,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-01','2017-12-31',11002,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25533,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-31','2018-07-01',11004,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25534,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-01-19','2018-07-26',11005,21007,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25535,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-12','2018-04-29',11007,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25536,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-08-18','2018-02-05',11012,21004,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL);
2. Update the model #
As you can see, we’ve preserved the information about the five project managers by moving it to the relationship between Project_assignment and Project_role. Now we can proceed with updating the model:
- Save and close the SQL file; after that, empty the Cloudlet Workforce database by right-clicking on it and selecting Clear. Immediately after, drag the SQL file and drop it on the Cloudlet: the database will be repopulated with the data contained in the file.
- At this point we can finally eliminate the association between Project and Employee: open TutorialEngine and, from the Database Schema , right click on it, select
Deleteand confirm, doing the same for the orphaned comment; after that, save the model and close the Designer.
3. Check the changes #
Now all that remains is to delete all traces of the previous association from the database: from the Dashboard, open the database panel and resolve the medium severity issue. After that, start the Cloudlet, log in as the default member and check that in the generated application the assignments for the project directors actually indicate the Director role. For this purpose, it may be useful for you to examine the list of all Project_assignment enabled in the Administration view.
Real scenarios #
Before concluding the article, it is appropriate to comment on the proposed solution and clarify our intent. In the exercise we have made the hypothesis that it was possible to easily modify the data via text file ’ dealing with a few lines ’ not taking into account, then, the amount of downtime required for the system during the three phases of model modification, data modification and system alignment; in particular, the latter includes both the time that must be waited for the process of importing the database, and that employed for regenerating and restarting the Cloudlet.
In real-world situations, a production system has hundreds of thousands of records in the database and high service availability is required; moreover, morphing must be able to occur in a secure way in a protected environment, similar to what Livebase offers in managing model updates.
For these reasons, there are at least two approaches to solving problems similar to the one we have described:
- The first one consists in replicating the database in a separate environment from the production one, and ’ exploiting some ETL software ’ operate the required transformations, after which replace the production database with the updated one after a service interruption.
- The second method consists in configuring an ad-hoc extension of the Cloudlet using the plugin mechanism supported by Livebase, which will programmatically update the data in real time, allowing a gradual change of the database and ensuring the uninterrupted availability of the service.
Both approaches are made possible by the DatabaseImporter/Exporter, the tool we presented, hence its importance.
Conclusions #
With this we have exhausted the basic aspects of modeling, Cloudlet management, generated application interaction and maintenance. Congratulations, you have concluded the Tutorial!
Click on the button to download the model we made in this lesson:
Should you have any concerns or questions of any kind, you can contact us at info@fhoster.com. Thank you for your attention, and we wish you a good development with Livebase!