Nella lezione precedente #
Abbiamo sfruttato le tecniche di partizionamento verticale, orizzontale e per profilo utente per realizzare delle viste applicative, incentrata ognuna su una particolare figura elencata nella sezione Profili utente del nostro scenario d’esempio, ottenendo così una piccola applicazione gestionale completa.
Tuttavia, le scelte di progettazione adottate finora hanno ipotizzato che la nostra applicazione non subisca cambiamenti significativi durante il suo esercizio, mentre in uno scenario reale le richieste di nuove funzionalità o di correzione dei bug potrebbero comportare interventi di manutenzione molto complessi, per cui non sono sufficienti le strategie automatiche offerte da Livebase.
Un limite della manutenzione evolutiva automatica #
Parlando della manutenzione evolutiva, abbiamo affermato che…
Una delle principali sfide nel modificare un’applicazione in esercizio sta nel prestare attenzione a non rompere nulla o rendere inconsistenti i dati presenti sul database.
Ragioniamo sul rapporto tra struttura e contenuto di un database: gli elementi che possiamo definire nel Database Schema (classi, attributi e relazioni) sono i contenitori della nostra informazione. Come sappiamo, con il Designer Livebase possiamo modificare la dimensione (dominio e cardinalità) o il tipo di informazione (tipo di dato) di questi contenitori; tuttavia, si tratta di modifiche strutturali che non interessano direttamente i dati in essi contenuti.
Quando i contenitori non sono vuoti – ovvero, il modello è legato a un database – tali modifiche si ripercuotono direttamente sui dati preesistenti. Sebbene sia sempre possibile controllare gli effetti delle modifiche grazie allo strumento di allineamento, la dipendenza dell’informazione dalla struttura del database è un vincolo che limita il nostro potere espressivo, e può quindi rappresentare un ostacolo per l’evoluzione del sistema.
- Cosa succede se vogliamo spostare l’informazione su un contenitore diverso? Ad esempio, vorrei spostare l’informazione associata a una relazione tra due classi su un attributo di un’altra classe.
Conosci già la risposta a questa domanda: in 6 – Modellare con le relazioni: quando abbiamo promosso alcuni attributi della classe Employee (position e team) reificandoli in nuove classi satellite, i dati memorizzati in precedenza nelle colonne relative a quegli attributi sono rimasti orfani e abbiamo dovuto rinunciarvi. Chiaramente quest’operazione è accettabile finché si rimane in un contesto sandbox, ma come ci saremmo dovuti comportare se si fosse trattato di un sistema in produzione?
Per non perdere quei dati avremmo dovuto:
- Consentire – per un breve periodo di tempo – la coesistenza dei “nuovi” e “vecchi” contenitori, adeguando opportunamente lo spazio dei nomi.
- Rigenerare l’applicazione e aggiornare la struttura del database.
- Spostare a mano, per ciascun impiegato, le informazioni sulla posizione e sul team nelle nuove classi.
Chiaramente questa soluzione non può scalare, perché introduce potenziali ambiguità e può risultare un processo troppo lento in presenza di grosse moli di dati. Esiste un approccio smart per risolvere questo problema?
![]() In questo articolo vediamo quindi come affrontare gli scenari di manutenzione evolutiva che Livebase non è in grado di gestire automaticamente. Lo strumento che utilizziamo è il Database Importer, una utility che consente di gestire il database di una Cloudlet indipendentemente da tutti gli altri suoi componenti; in pratica, possiamo importare/esportare l’intero database sotto forma di file SQL e operare direttamente su tale file. Ciò ci permette di effettuare in poco tempo una manipolazione di massa sui dati a cui vorremo “cambiare contenitore”.
In questo articolo vediamo quindi come affrontare gli scenari di manutenzione evolutiva che Livebase non è in grado di gestire automaticamente. Lo strumento che utilizziamo è il Database Importer, una utility che consente di gestire il database di una Cloudlet indipendentemente da tutti gli altri suoi componenti; in pratica, possiamo importare/esportare l’intero database sotto forma di file SQL e operare direttamente su tale file. Ciò ci permette di effettuare in poco tempo una manipolazione di massa sui dati a cui vorremo “cambiare contenitore”.
Importare dati mediante file SQL #
Per prima cosa prepariamo l’ambiente di lavoro: abbiamo bisogno di una Cloudlet, un modello e dei dati su cui lavorare.
A questo punto dovresti avere a disposizione la versione finale del modello TutorialEngine. Se così non fosse, scaricalo cliccando sul bottone a fianco; trascina poi il file XML sulla Dashboard per importarlo nella libreria.
Installa il modello su una Cloudlet: può essere una Cloudlet nuova o la Cloudlet Workforce con cui abbiamo lavorato finora. Se opti per una Cloudlet nuova, una volta installato il modello è necessario creare il database per poi svuotarlo, facendo clic con il destro sulla relativa icona e selezionando Clear: questa procedura serve a evitare che la classe Enum Activity_type, introdotta nella lezione Modella query e filtri, interferisca con il successivo processo di importazione dei dati. Se invece desideri continuare a utilizzare Workforce, dovrai solo svuotare il database già presente facendo Clear. In ogni caso, ricorda di riallineare il database al modello risolvendo eventuali compatibility issue.
Ora dobbiamo importare dei dati. Per questo esercizio abbiamo preparato un file contenente un dataset di prova per il database di Workforce: scaricalo cliccando sul bottone a fianco, dopodiché apri il pannello database della Cloudlet destinazione, clicca su Upload e seleziona il file SQL appena scaricato.
Il database verrà popolato con 208 record, ripartiti come indicato in figura tra tutte le classi del modello. Nella pratica, il file che abbiamo usato contiene diverse query SQL di tipo INSERT per ciascuna tabella mappata nel database.
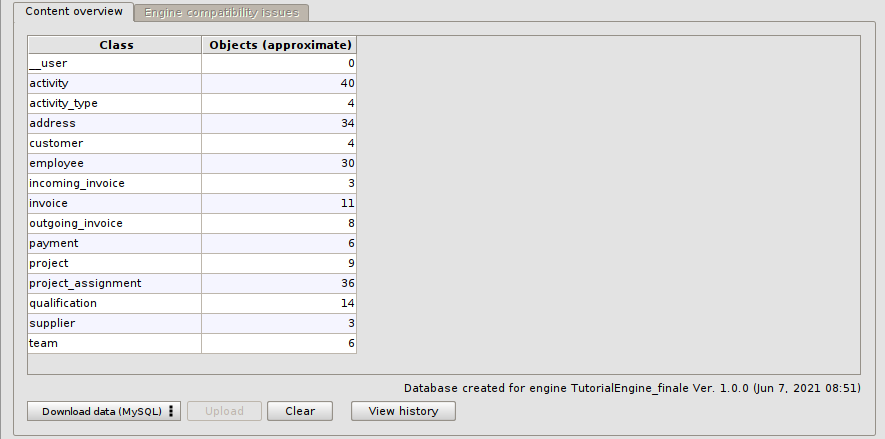
Generalizzare una relazione complessa #
Diamo un’occhiata nel Designer a TutorialEngine: in questo contesto ignoriamo la maggior parte dei dettagli del modello – i cui requisiti sono descritti nello Scenario di esempio – e ci concentriamo sull’evoluzione di una porzione del Database Schema .
Spostati sul diagramma Staff e osserva la relazione tra le classi Project ed Employee.
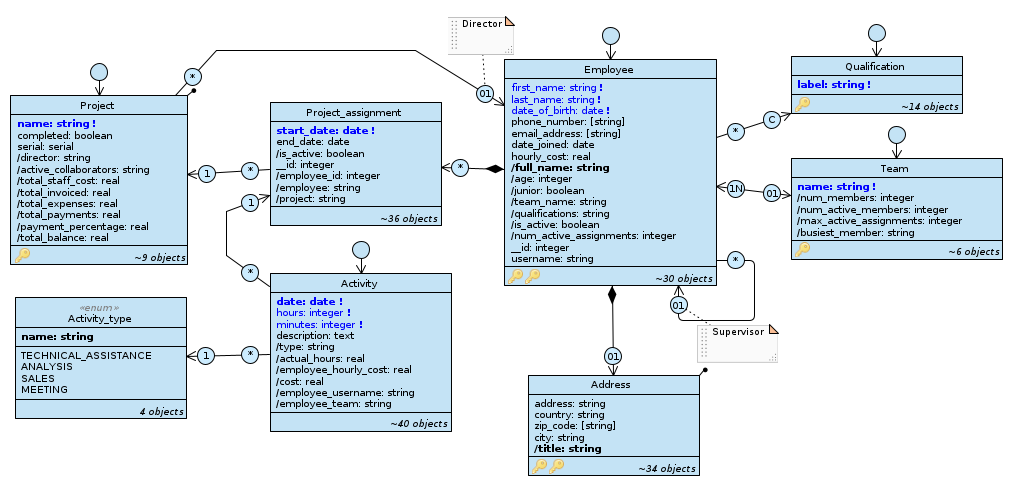
Il diagramma Staff.
Per ciascun progetto possiamo indicare l’impiegato che ricopre il ruolo di direttore; questo viene opportunamente scelto – mediante regole di filtraggio a livello di applicazione – tra gli impiegati che in quel momento sono assegnati al progetto tramite un incarico attivo – rappresentati dall’assegnazione con la classe Project_assignment, classe part di Employee.
Le informazioni che legano impiegato e progetto sono le date di inizio/fine incarico e la proprietà di essere o meno direttore; in particolare quest’ultima è espressa con una relazione speciale da Project a Employee. Uno dei problemi di questa rappresentazione è che non è possibile accedervi dalla lista degli impiegati ma solo da quella dei progetti; un altro è che non è sufficientemente flessibile:
- Cosa dovremmo fare se volessimo rappresentare e gestire dinamicamente anche altri ruoli che possono essere assunti nel progetto, come ad esempio responsabile tecnico, business analyst o staff generico?
Chiaramente aggiungere altri ruoli di associazione speciali non risolve il problema, perché risulterebbe in un aumento di complessità del modello e ci costringerebbe ad effettuarne il rebuild ogni volta. Non possiamo neanche utilizzare una Enum come abbiamo fatto con Activity_type nella lezione Modella query e filtri, perché non conosciamo a priori tutti i possibili Project_role che possono essere assunti da un impiegato. La soluzione anche in questo caso è incapsulare l’informazione in una generica classe satellite, Tuttavia, a differenza di quanto abbiamo fatto in precedenza, ora manterremo la relazione esistente finché non potremo eliminarla senza rischi.
Modifica il modello dati #
Per prima cosa, crea la classe Project_role con l’attributo name come in figura, impostato come required, object title e univoco.
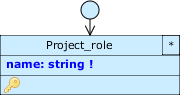
Chiaramente non possiamo far ricoprire un ruolo per un progetto a un impiegato che non ci lavora; pertanto, questa informazione è in relazione con l’incarico dell’impiegato:
Aggiungi un’associazione unidirezionale da Project_assignment a Project_role, rinomina i ruoli in assignments e role_e imposta a (01) la cardinalità di quest’ultimo (il ruolo è unico per ciascun incarico, il vincolo è rilassato per non introdurre problemi di allineamento con i dati sottostanti). Dopodiché, trascina name su Project_assignment e rinomina la query in /role.
In questo modo, ogni volta che creiamo un nuovo incarico per un impiegato, dovremo specificare anche quale ruolo ricoprirà in quel progetto.
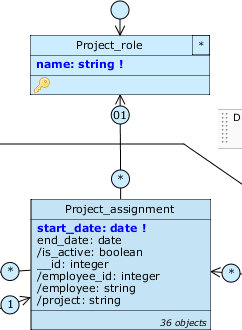
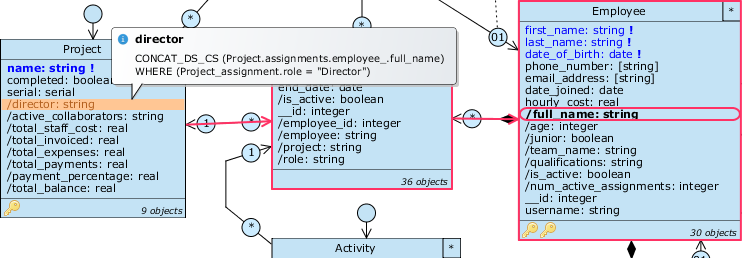
Ora che abbiamo una nuova struttura, possiamo operare dei cambiamenti a costo zero su quella esistente: cominciamo reindirizzando la query /director su Project che mostra il nome del direttore, passando attualmente per Project.role:
- Fai click destro su
/directore selezionaReroute, poi scegli il percorsoProject.assignments.employee_.full_name; dato che il nuovo path attraversa ruoli a molti, si aprirà il Query expression editor per chiederci come aggregare la query più valori. - Chiaramente siamo interessati a mostrare il nome di un unico impiegato, pertanto dobbiamo fare in modo che ci sia un solo incarico con ruolo “direttore” per ciascun progetto. Per prima cosa, aggiungi la filter condition
Project_assignment.role = "Director"e aggrega con la funzioneConcat distinct(per rappresentare il contenuto della stringa /full_name); in questo modo verranno mostrati tutti gli impiegati che assumono il ruolo di direttore per quel progetto.
Ora occupiamoci di ridefinire la regola che regoli il numero di ruoli “direttore” per progetto, in modo che /director mostri al più il nome di un solo impiegato. Dobbiamo definire un Class warning per impedire di salvare nuovi assignment con ruolo “direttore” se ne è presente già uno associato allo stesso progetto.
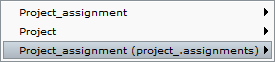
- Prima di tutto, dobbiamo contare quanti direttori ci sono per ciascun progetto; tuttavia, dal momento che il Class warning può usare solo gli attributi presenti nella classe, dobbiamo memorizzare questa informazione dentro Project_assignment e per fare ciò procediamo in modo leggermente diverso dal solito, creando una query rientrante: dal Class menu di Project_assignment seleziona
New derived attribute→Query, espandi il pathProject_assignment.project_.assignments.__ide aggrega conCount distinct. - Anche qui definiamo una filter condition sul nome del ruolo, ma dobbiamo prestare particolare attenzione alla scelta della classe: lungo il percorso, infatti, attraversiamo due volte Project_assignment: la prima volta si tratta di un oggetto singolo (su cui verrà memorizzato /numdirectors), la seconda si tratta dell’insieme di assignment associati a un progetto mediante il ruolo Project.assignments.
Puoi verificarlo aprendo l’expression editor della filter condition e cliccando sull’icona : nota come Project_assignment sia riportata due volte, con la seconda che specifica il path rientrante project._assignments. Dato che dobbiamo filtrare su questo insieme, espandi questa voce, seleziona l’attributoProject_assignment.project_.assignments.rolee completa l’espressione aggiungendo= "Director". Conferma la creazione della query e rinominala in/num_directors. - Come puoi vedere in figura, la query percorre l’associazione in entrambe le direzioni, uscendo e rientrando sulla stessa classe.
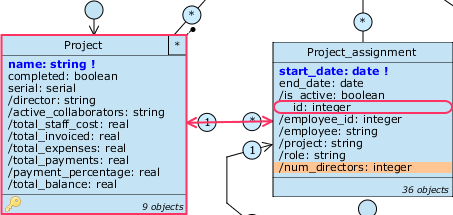
In questo modo, gli incarichi assegnati allo stesso progetto avranno tutti lo stesso valore di /num_directors, questo effetto è desiderato, perché serve al warning per essere valutato correttamente per ogni oggetto.  Spostati sulla vista applicativa Administration e aggiungi un warning bloccante su Project_assignment chiamato
Spostati sulla vista applicativa Administration e aggiungi un warning bloccante su Project_assignment chiamato tooManyDirectorscon l’espressionenum_directors > 1; spunta le azioniSaveNeweSaveExisting, digita il messaggio “There would be too many director assignments for the selected project.” e conferma.- Propaghiamo il warning sulle altre viste: dal Class warnings manager, selezionalo e spunta l’opzione
Copy warning to other applications.
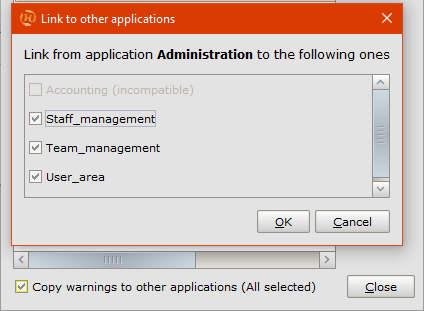
- Dal pannello che comparirà seleziona le tre viste compatibili, ovvero quelle in cui Project_assignment è abilitata. Fatto questo, conferma e ritorna al diagramma.
Così facendo, abbiamo preparato il terreno per l’introduzione dei nuovi ruoli di progetto. Ora non ci resta che allineare i dati esistenti relativi ai direttori di progetto. Salva e chiudi il Designer.
Allinea i dati via SQL #
Il database mostra delle issue di bassa severità, relative alla creazione della nuova tabella Project_role: risolvile senza problemi, poi procediamo nel manipolare i nostri dati.
Dobbiamo modificare il file SQL che popola il database. In questo caso non è necessario riscaricarlo dalla Cloudlet, in quanto non abbiamo effettuato modifiche sul contenuto del database; pertanto possiamo lavorare direttamente sul file Workforce_data.sql che hai scaricato in precedenza.
Dato che stiamo lavorando su un database abbastanza piccolo, per questa parte dell’esercizio possiamo operare direttamente sul contenuto del file; pertanto, aprilo utilizzando un qualsiasi editor di testo (noi abbiamo usato Sublime Text).
1. Modifica il file SQL #
Il file si presenta come in figura. Come puoi notare, contiene diverse query INSERT INTO, una per ogni tabella del database relativa a una classe del modello. Inoltre, ci sono alcune tabelle aggiuntive che mappano le relazioni molti-a-molti (join tables), come ad esempio quella tra Employee e Qualification (employee_qualification).
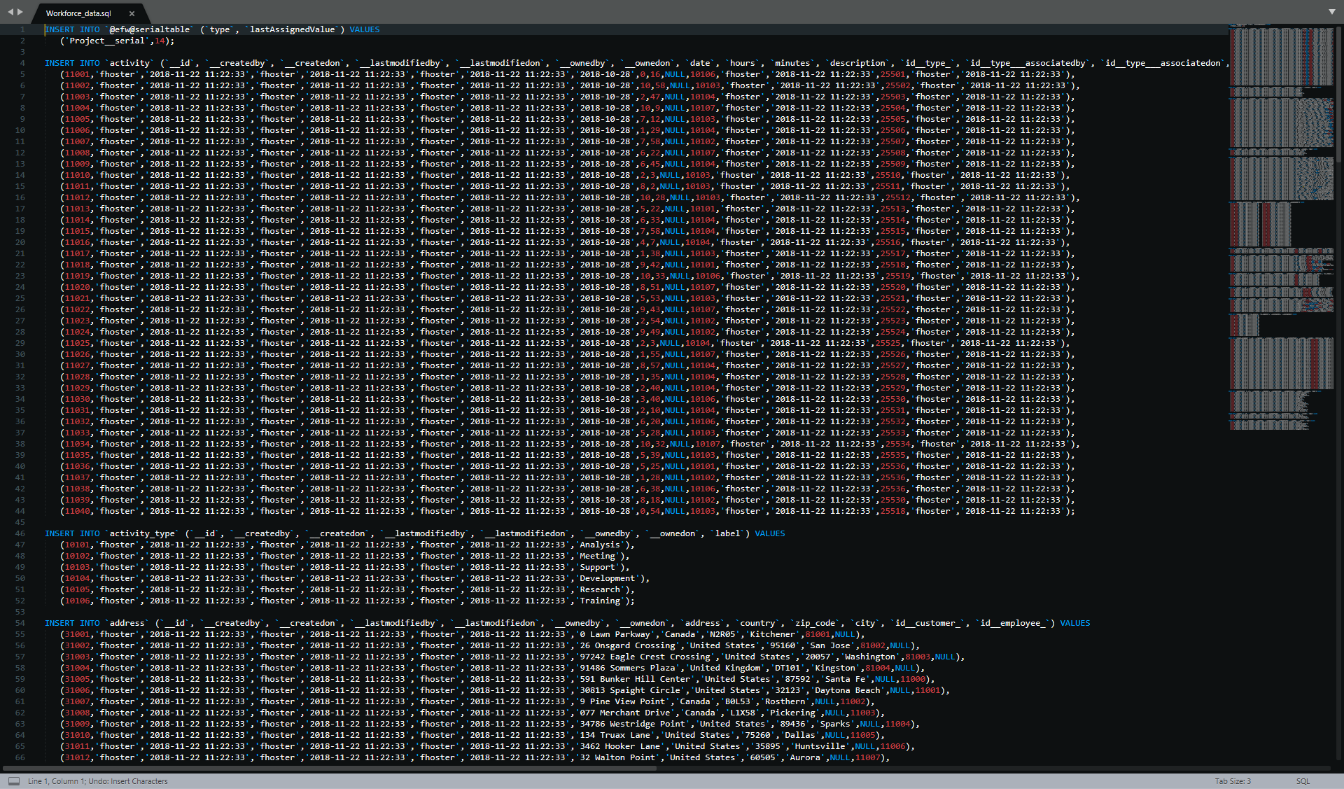
Cominciamo aggiungendo dei nuovi record project_role; a tal proposito, nota come le query esplicitino anche i valori assunti dai Platform attributes di ogni oggetto (come __id, __createdBy, __createdOn, eccetera). Pertanto, dovremo compilare anche quei campi. Aggiungi le seguenti righe in coda al file che aggiungono i ruoli Director, Technical Manager, Account Manager, Staff.
INSERT INTO `project_role` (`__id`, `__createdby`, `__createdon`, `__lastmodifiedby`, `__lastmodifiedon`, `__ownedby`, `__ownedon`,`name`) VALUES
(29901,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Director'),
(29902,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Technical Manager'),
(29903,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Account Manager'),
(29904,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','Staff');
Informazioni come data di creazione e autore delle modifiche possono essere qualsiasi, a patto che rispettino il formato delle colonne che vanno a popolare. Un discorso a parte vale per gli __id, che come sappiamo devono essere univoci in tutto il database. Più avanti torneremo su questo argomento.
Ora dobbiamo localizzare la query INSERT INTO 'project' e prendere nota dei valori presenti sotto la colonna id_director, ovvero degli ID dei direttori. Ad esempio, il progetto con ID 21001 (“Mars Rocket”) ha come direttore l’impiegato 11011 (“Mal Cragell”); infatti, possiamo trovare un record con quell’ID sotto la query INSERT INTO 'employee'.
Le coppie direttore-progetto sono quindi quelle riportate nella tabella a fianco. Come puoi notare, alcuni progetti non hanno un direttore; in tal caso, il valore della colonna id_director è NULL, così come quello delle colonne id__director_associatedby e id__director_associatedon, relative ai platform attribute della singola associazione.
| Impiegato | Progetto |
|---|---|
11011 | 21001 |
11003 | 21002 |
11004 | 21005 |
11021 | 21008 |
11008 | 21009 |
Fatto questo, dobbiamo modificare i record della query INSERT INTO ‘project_assignment’ relativi agli incarichi dei direttori di ciascun progetto. Data la struttura del nostro modello, sappiamo certamente che questi record esistono.
La nuova relazione va da più Project_assignment a un singolo Project_role, quindi negli oggetti della prima classe sarà presente una chiave che referenzia il ruolo (detta foreign key). Per prima cosa, dobbiamo modificare l’intestazione della query e aggiungere in coda questa chiave, insieme ai due platform attributes dell’associazione. La riga seguente:
INSERT INTO `project_assignment` (
`__id`,
`__createdby`,
`__createdon`,
`__lastmodifiedby`,
`__lastmodifiedon`,
`__ownedby`,
`__ownedon`,
`start_date`,
`end_date`,
`id__employee_`,
`id__project_`,
`id__project___associatedby`,
`id__project___associatedon`
) VALUES
diventa
INSERT INTO `project_assignment` (
`__id`,
`__createdby`,
`__createdon`,
`__lastmodifiedby`,
`__lastmodifiedon`,
`__ownedby`,
`__ownedon`,
`start_date`,
`end_date`,
`id__employee_`,
`id__project_`,
`id__project___associatedby`,
`id__project___associatedon`,
`id__role_`, --- new
`id__role___associatedby`, --- new
`id__role___associatedon` --- new
) VALUES
Dopodiché, dobbiamo localizzare gli incarichi dove le coppia id__employee e id__project coincidono con le quelle riportate nella tabella sopra. A questi record dobbiamo associare il project_role “Director”, ovvero quello da noi aggiunto con l’ID 29901.
Nella tabella a fianco abbiamo riportato le triple impiegato-progetto-incarico su cui effettuiamo questa modifica. Nota bene che per questi record vanno specificati anche i platform attributes associatedBy e associatedOn, mentre per tutti gli altri record – dato che il vincolo è rilassato – possiamo indicare NULL per tutti e tre i nuovi campi.
| Impiegato | Progetto | Incarico |
|---|---|---|
11011 | 21001 | 25512 |
11003 | 21002 | 25520 |
11004 | 21005 | 25505 |
11021 | 21008 | 25522 |
11008 | 21009 | 25509 |
La nuova query risultante è la seguente, in cui abbiamo evidenziato i cambiamenti. Copiala e sostituiscila a quella esistente.
INSERT INTO `project_assignment` (`__id`, `__createdby`, `__createdon`, `__lastmodifiedby`, `__lastmodifiedon`, `__ownedby`, `__ownedon`, `start_date`, `end_date`, `id__employee_`, `id__project_`, `id__project___associatedby`, `id__project___associatedon`,`id__role_`, `id__role___associatedby`, `id__role___associatedon`) VALUES
(25501,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-08-16','2018-02-13',11000,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25502,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-02','2019-02-22',11001,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25503,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-08-07','2018-09-01',11002,21003,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25504,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-04','2018-09-17',11003,21004,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25505,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-17','2019-01-30',11004,21005,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25506,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-13','2018-05-25',11005,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25507,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-10','2018-09-07',11006,21007,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25508,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-04-21','2018-05-24',11007,21008,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25509,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-25','2019-01-03',11008,21009,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25510,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-10-28','2018-04-14',11009,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25511,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-21','2019-02-10',11010,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25512,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-09','2019-02-05',11011,21001,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25513,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-02-13','2018-05-08',11012,21005,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25514,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-26','2018-05-03',11013,21005,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25515,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-11-29','2018-04-19',11014,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25516,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-08-23','2017-10-30',11015,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25517,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-11-21','2019-01-01',11016,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25518,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-09-24','2018-11-21',11017,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25519,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-06-20','2018-11-21',11018,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25520,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-09-29','2018-03-13',11019,21002,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25521,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-09','2018-06-02',11020,21003,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25522,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-09-27','2018-11-30',11021,21008,'fhoster','2018-11-22 11:22:33',29901,'fhoster','2018-11-22 11:22:33'),
(25523,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-06-13','2017-12-01',11022,21009,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25524,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-02-16','2018-04-08',11023,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25525,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-06-04','2017-10-19',11024,21005,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25526,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-04-12','2018-09-22',11025,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25527,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-08-10','2018-11-30',11026,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25528,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-01-27','2018-08-18',11027,21008,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25529,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-03','2018-11-14',11028,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25530,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-10-15','2018-03-07',11029,21002,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25531,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-10-10','2018-11-03',11002,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25532,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-01','2017-12-31',11002,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25533,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-12-31','2018-07-01',11004,21006,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25534,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-01-19','2018-07-26',11005,21007,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25535,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2018-03-12','2018-04-29',11007,21001,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL),
(25536,'fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','fhoster','2018-11-22 11:22:33','2017-08-18','2018-02-05',11012,21004,'fhoster','2018-11-22 11:22:33',NULL, NULL, NULL);
2. Aggiorna il modello #
Come puoi notare, abbiamo preservato l’informazione relativa ai cinque direttori di progetto, spostandola sulla relazione tra Project_assignment e Project_role. Ora possiamo procedere nell’aggiornamento del modello:
- Salva e chiudi il file SQL; dopodiché, svuota il database della Cloudlet Workforce facendo click destro su di esso e selezionando Clear. Subito dopo, trascina il file SQL e rilascialo sulla Cloudlet: il database sarà ripopolato con i dati contenuti nel file.
- A questo punto possiamo finalmente eliminare l’associazione tra Project ed Employee: apri TutorialEngine e, dal Database Schema , fai click destro su essa, seleziona
Deletee conferma, facendo lo stesso per il commento rimasto orfano; dopodiché, salva il modello e chiudi il Designer.
3. Controlla le modifiche #
Adesso non rimane altro che eliminare dal database ogni traccia della precedente associazione: dalla Dashboard, apri il pannello database e risolvi la medium severity issue. Dopo ciò, avvia la Cloudlet, accedi come il default member e verifica che nell’applicazione generata gli assignment relativi ai direttori di progetto indichino effettivamente il ruolo Director. A tale scopo, può tornarti utile esaminare la lista di tutti i Project_assignment abilitata nella vista Administration.
Scenari reali #
Prima di concludere l’articolo, è opportuno fare delle osservazioni sulla soluzione proposta e chiarificare i nostri intenti. Nell’esercizio abbiamo fatto l’ipotesi che fosse possibile modificare agilmente i dati via file di testo – trattandosi di poche righe – non tenendo conto, poi, della quantità di downtime richiesta per il sistema durante le tre fasi di modifica del modello, modifica dei dati e allineamento del sistema; in particolare, quest’ultima comprende sia il tempo che occorre attendere per il processo di importazione del database, che quello impiegato per la rigenerare e riavviare la Cloudlet.
In situazioni reali, un sistema in produzione ha centinaia di migliaia di record nel database ed è richiesta un’alta disponibilità del servizio; inoltre, il morphing deve poter avvenire in un modo sicuro in un ambiente protetto, in modo analogo a quanto offerto da Livebase nella gestione degli aggiornamenti del modello.
Per questi motivi, esistono almeno due approcci per risolvere problemi simili a quello che abbiamo descritto:
- Il primo consiste nel replicare il database in un ambiente separato da quello di produzione, e – sfruttando un qualche software di ETL – operare le trasformazioni richieste, dopodiché sostituire il database in produzione con quello aggiornato previa interruzione di servizio.
- Il secondo metodo consiste nel configurare un’estensione ad-hoc della Cloudlet mediante il meccanismo di plugin supportato da Livebase, che si occupi – in completa autonomia – aggiornare programmaticamente i dati presenti in tempo reale, consentendo un cambiamento graduale del database e garantendo la disponibilità ininterrotta del servizio.
Entrambi gli approcci sono resi possibili dal DatabaseImporter/Exporter, lo strumento che abbiamo presentato, da questo ne deriva la sua importanza.
Conclusioni #
Con questo abbiamo esaurito gli aspetti fondamentali di modellazione, gestione della Cloudlet, interazione con l’applicazione generata e manutenzione. Complimenti, hai concluso il Tutorial!
Clicca sul bottone per scaricare il modello che abbiamo realizzato in questa lezione:
Se dovessi avere dubbi o domande di qualsiasi tipo, puoi contattarci all’indirizzo info@fhoster.com. Ti ringraziamo per l’attenzione, e ti auguriamo un buono sviluppo con Livebase!